While my microblog isn’t exactly short, it is definitely shorter than my typical technical blog posts. You will probably see some parallels between my microblog and the blogs I post here. This is because some of the technical aspects of the micro posts are the quick scratch notes that gives an overview of the topic I wish to write about on this blog site.
You can visit my microblog if you are interested: Random Bits
Complete List
- [2024-12-29] New Laptop: Framework 16
- [2024-12-29] Utilizing Aliases and Interactive Mode to Force Users to Think Twice Before Deleting Files
- [2024-12-20] Stack Overflow: The Case of a Small Stack
- [2024-12-17] Jekyll Cache Saving the Day
- [2024-11-09] QNX is 'Free' to Use
- [2024-10-08] [Preview] Manually Verifying an Email Signature
- [2024-10-06] [Preview] Half-Width and Full-Width Characters
- [2024-09-18] Mixing Number and String
- [2024-08-30] `.` At The End of a URL
- [2024-08-28] Splitting Pdfs into Even and Odd Pages
- [2024-08-28] Executing Script Loophole
- [2024-08-24] Replacing main()
- [2024-08-18] Editing GIFS and Creating 88x31 Buttons
- [2024-08-10] multiple definition of `variable` ... first defined here
- [2024-08-04] Delusional Dream of a OpenPower Framework Laptop
- [2024-08-04] 2024 Update
New Laptop: Framework 16
December 29, 2024
Ever since Linus Tech Tips (LTT) introduced Framework, a repairable and modular laptop, back in 2021, I always wanted one for myself. I always loved the idea of modular electronics ever since PhoneBloks introduced their idea of modular phones. Electronics that are modular are usually highly repairable due to the fact that one can easily swap a faulty component with a new component instead of going to a repair shop or dumping the phone into the garbage. The appeal of bringing the desktop experience of being able to upgrade various parts such as the CPU, RAM and storage to the laptop was very appealing. Electronics of the past were much easier to repair and upgrade but these days laptops are designed to not be easily upgradable such as the use of soldered RAM. Laptops are also designed to not be as repairable as it once was with the use of integrating more components into the SoC which allows manufacturers to significantly design a more compact and sleeker device. There are lots of benefits of SoC than just compactness, it also can help with power efficiency and speed as it can be optimized to have fast access to both the CPU and memory. While there could be engineering reasons to soldered RAM, it is likely to also encourage consumers to purchase a new laptop instead.

A Framework laptop and its various parts. Source: Framework
The Framework laptop is great but every criticism you have heard about the Framework laptop holds true. Cost is the biggest issue with Framework laptops. As Framework is a small company, it cannot build in scale unlike the other OEMs. You will be paying an extremely hefty price to obtain a modular laptop. You could get a laptop from other OEMs with better specs for way less than what Framework offers. The laptop is not suitable for the regular consumers and is way more expensive than a luxurious laptop (aka Macbooks). There are other issues with the Framework laptop but I consider this to not be the cost of Framework but rather the cost of modularity. As I mentioned earlier, there are tradeoffs between modularity and integrating everything into an SoC. When you are getting a Framework laptop, you are buying the laptop for its modularity and repairability. For instance, when you buy a Framework 16 for instance, you can see the outlines of the various sliders around the keyboard and touchpad. In addition, you can clearly see the outlines of each expansion card on the laptop.
On a very positive note, you can swap the expansion cards to fit your needs and for those who care about colors, you can easily swap the colors of the screen bezel and the panels surrounding the keyboard such as adding a numpad, swapping the keyboard for an RGB keyboard, or getting an LED matrix panel. The flexibility to change the expansion cards was the biggest appeal of the laptop for me as you get to choose which IO ports will be HDMI, USB-As, or USB-Cs (with some restrictions).
I should keep this more brief as this is a microblog … Anyhow, now that I have access to my first dedicated GPU, I can now play video games that isn’t Minesweeper, Solitaire, Starcraft (Broodwar) and PC ports of old games like Final Fantasy 7. Ever since players were forced to move onto Counterstrike 2, I was no longer able to play CounterStrike with my old Lenovo Gen 7 X1 Carbon laptop. I was surprised by how noisy the laptop can be when playing Counterstrike 2 though that is likely due to my inexperience playing videogames that requires a dedicated GPU (and I am playing on a laptop which is probably not the best idea if you want to play videogames). Here’s the specs:
$ neofetch
.',;::::;,'. zaku@fedora
.';:cccccccccccc:;,. -----------
.;cccccccccccccccccccccc;. OS: Fedora Linux 40 (Workstation Edition) x86_64
.:cccccccccccccccccccccccccc:. Host: Laptop 16 (AMD Ryzen 7040 Series) AJ
.;ccccccccccccc;.:dddl:.;ccccccc;. Kernel: 6.11.4-201.fc40.x86_64
.:ccccccccccccc;OWMKOOXMWd;ccccccc:. Uptime: 5 hours, 46 mins
.:ccccccccccccc;KMMc;cc;xMMc:ccccccc:. Packages: 2254 (rpm), 12 (flatpak)
,cccccccccccccc;MMM.;cc;;WW::cccccccc, Shell: bash 5.2.26
:cccccccccccccc;MMM.;cccccccccccccccc: Resolution: 1920x1080
:ccccccc;oxOOOo;MMM0OOk.;cccccccccccc: DE: GNOME 46.6
cccccc:0MMKxdd:;MMMkddc.;cccccccccccc; WM: Mutter
ccccc:XM0';cccc;MMM.;cccccccccccccccc' WM Theme: Adwaita
ccccc;MMo;ccccc;MMW.;ccccccccccccccc; Theme: Adwaita [GTK2/3]
ccccc;0MNc.ccc.xMMd:ccccccccccccccc; Icons: Adwaita [GTK2/3]
cccccc;dNMWXXXWM0::cccccccccccccc:, Terminal: gnome-terminal
cccccccc;.:odl:.;cccccccccccccc:,. CPU: AMD Ryzen 9 7940HS w/ Radeon 780M Graphics (16) @ 5.263GHz
:cccccccccccccccccccccccccccc:'. GPU: AMD ATI c4:00.0 Phoenix1
.:cccccccccccccccccccccc:;,.. GPU: AMD ATI Radeon RX 7600/7600 XT/7600M XT/7600S/7700S / PRO W7600
'::cccccccccccccc::;,. Memory: 7192MiB / 31386MiB
On OpenBlender Benchmark:
monster: 130.805407
junkshop: 85.742239
classroom:64.374681
Which is significantly better than what my X1 Carbon achieved (where higher numbers are better).
Utilizing Aliases and Interactive Mode to Force Users to Think Twice Before Deleting Files
December 29, 2024
I previously mentioned that I lost my file by accidentally overwriting my file using the cp command. This got me thinking as to why this would be impossible on
my work laptop since I would be constantly bombarded with a prompt to confirm my intention to overwrite the file.
$ cp 2024-12-01-template.md 2024-12-30-alias-interactive.md
cp: overwrite '2024-12-30-alias-interactive.md'?
Commands like mv and cp have an interactive flag -i to prompt before overwriting the file. As seen in man 1 cp
-i, --interactive
prompt before overwrite (overrides a previous -n option)
To force everyone at work to have this flag enabled, they made cp and mv an alias in our default shell configs:
alias cp="cp -i"
alias mv="mv -i"
Which you can also verify using the type command:
$ type cp
cp is aliased to `cp -i'
$ type mv
mv is aliased to `mv -i'
Stack Overflow: The Case of a Small Stack
December 20, 2024
Years ago I was once asked by an intern to debug a mysterious crash that seemed so innocent. While I no longer recall what the code was about, we stripped the program to a single line in
main. Yet the program still continued to crash.
Source:
int main() {
char buf[1024*1024*1024];
}Result:
# ./prog-arm64
Process 630803 (prog-arm64) terminated SIGSEGV code=1 fltno=11 ip=00000025333267f0 mapaddr=00000000000007f0 ref=000000443dd5dc50
Memory fault (core dumped)
This bewildered all of the interns as it made absolutely no sense. Through our investigation, there was two things we noticed:
- The program worked on our local machines but not on our target virtual machine
- We were allocating an extremely large buffer in the stack which was unusual
It turns out the intern wanted to allocate a 1MiB buffer for some networking or driver related ticket. If I recall correctly, our target only had 512MB RAM so this could have explained the mysterious crash. But even 1MiB buffer on the stack was too large for our target:
Source:
int main() {
char buf[1024*1024];
}Result:
# ./prog-arm64
Process 696339 (prog-arm64) terminated SIGSEGV code=1 fltno=11 ip=0000004de7e7a7ec mapaddr=00000000000007ec ref=000000383b19fbe0
Memory fault (core dumped)
One thing I purposely omitted was that our target was running QNX, a realtime operating system. If we were to take a look at the documentation:
A process’s main thread starts with an automatically allocated 512 KB stack – QNX SDP 8.0 - Stack Allocation
This shocked all of us since 1 MiB is not a large buffer in 2021 where we had plenty of memory on our own personal system at home.
Note 1: The target used in the example was an aarch64le. This example will work on amd64 (x86_64) but requires you to add something such as a print statement
Note 2: QNX 8.0 was released to the general public in late 2023 or early 2024 so the actual target at the time when the question was asked was running either QNX 7.0 or QNX 7.1 (I do not recall which version)
The behavior for AMD64 (x86_64) as noted requires more fiddling to trigger a crash which came to my surprise. A slightly more detailed version will be released shortly on my blog
which will include a very brief reason as to why AMD64 doesn’t crash if nothing extra is added like a call to puts.
Jekyll Cache Saving the Day
December 17, 2024
I was in the midst of publishing a post on announcing that QNX released a non-commercial license which allows hobbyist to fiddle around
but I accidentally deleted my file using the cp command. This effectively killed my mood as I did not want to rewrite everything
from scratch. I then recall that Jekyll creates a cache to speed up the build process when converting markdown to HTML.
$ ls -ld .?* drwxr-xr-x. 1 zaku zaku 204 Dec 16 23:47 .git -rw-r--r--. 1 zaku zaku 0 Oct 20 19:55 .gitignore drwxr-xr-x. 1 zaku zaku 32 Oct 20 19:56 .jekyll-cache
If we were to traverse into the cache and into Jekyll-Converters--Markdown, you’ll see a lot of directories labelled what it appears to be in hex:
.jekyll-cache/Jekyll/Cache/Jekyll--Converters--Markdown$ ls 0e 1c 22 24 2e 37 3f 44 47 53 57 5d 62 66 6e 74 7b 84 8d 90 91 9c a7 a9 aa ab b1 b3 b6 c1 c6 cb d4 d5 e1 e2 ea f9 fc
Using my trust tool grep, I was able to patch up pieces of my work. However, as the purpose of Jekyll-Converters--Markdown is to
cache markdown files that have been converted to HTML, I obviously had to clean it up a bit but regardless, it was much faster than
to rewrite the entire article.
QNX is 'Free' to Use
November 9, 2024
Recently on Hackernews, a relations developer from QNX announced that QNX is now free for anything non-commercial. QNX also made an annoncement to the LinkedIn Community as well which was where I learned about it. For those who are not familiar with QNX, QNX is a properiety realtime operating system targetted for embedded systems and is installed in over 255 million vehicles. QNX has a great reputation for being reliable and safe embedded system to build software on top of due to its microarchitecture and compliance to many industrial and engineering design process which gives customers the ability to certify their software in safety critical systems more easily. What makes QNX appealing is a discussion on another time but for me, this is a good opportunity to fiddle around with the system. I was previously denied a license from my university who had an agreement with QNX and my attempts to get an educational license did not go far years ago.

Previously to gain access to QNX, one would have to either purchase a commericial license from QNX or have an academic license. This made hobbyists from having access to the operating system. With the non-commericial license, QNX is now open for those who are interested in running a RTOS in their hobby projects and for open source developers to port their software on QNX. QNX is a POSIX compliant software but as QNX was not open for public use, companies had to port open source projects into QNX such as ROS (Robotics Operating System which isn’t an actual OS). QNX also mentions the non-commercial license allows one to develop training materials and books on utilizing QNX which is frankly scarce outside of QNX authorized materials (i.e. QNX training, Foundary27, and QNX Documentation).

While the announcement is welcoming news for me who would love to tinker around, this is yet another product entering the hobbyist community late. The reason for the success of UNIX, Linux, RISCV, and ARM is the ease and availability of the product to hobbyists and students who later bring this to their workplace or make the product better. Closing access to technology is a receipe for disaster in the long-term in terms of gaining market advantage. This is exactly the reason why we see cloud corporations enticing either the student or the hobbyist population to have free (limited) access to their products and even at times sponsor events targeted towards them. Linux, BSD, and FreeRTOS being open source makes them the dominant OS among the tinkering community and have wide adoption in the market. Over the years, we have seen a shift from customers using commercial and custom grade hardware and software towards more open source or off the shelf solutions including on critical safety applications such as those on SpaceX using Linux and non radiation hardened CPUs. IBM for instance has been late to developing an ecosystem of developers for their Cloud, Database and Power Architecture. IBM over the recent years has done a good job in creating free developer focused trainings which tries to make use of their own technologies. However, it is plain obvious that IBM has failed to capture mainstream interest of hobbyists who much prefer other cloud providers such as AWS, Google Cloud, Linode, and Digital Ocean. The SPARC and POWER architectures were open-source far too late by their own respective owners that developers have shifted towards RISCV and ARM as those architectures are either more open or easier to obtain (such as through Raspberry Pi Foundation).
While I have not done any sentimental analysis of this announcement, I think overall this move is a good first step to develop an ecosystem of developers who appreciate and understand the QNX architecture but is also met with sketpicism. For reference, QNX has messed with the community twice before which explains the big mistrust from experienced developers. The top comment on Hackernews does a great job summarizing the sketpicism. QNX used to have a bigger hobbyist community in the past where open source projects such as Firefox would have a build for QNX, but that all died when QNX closed their doors to the community. Years later, QNX source code was available for the public to read (though probably with restrictions) but later shut the source code availability after being acquired by Blackberry who does not have the best reputation to the developer community (hence why Blackberry Phones failed to capture the market from my understanding despite once being a market leader).
Regardless, I have plans to create a few materials on QNX in the coming months and perhaps create a follow up to QNX Adapative Partitioning System as it seemed to have gained enough has been ranked top 5 on Google search results (though I doubt it had many readers due to the population of QNX developers):

Google Search Console from July 9 2023 - Nov 8 2024 which had 308 clicks
[Preview] Manually Verifying an Email Signature
October 8, 2024
I noticed that the neocities community love using protonmail and some even share their public key to enable full encryption communication. While I care about cyber security more than the average human, I do not care enough to start requiring others to start encrypting their email and sign their messages so that I can verify the authenticity of the messages I receieve.
Out of curiosity, I decided to see how one would manually verify the signature of an email to ensure that the email has not been tampered with and comes from the person who it claims to be. I won’t go into how digital signatures work as those details will be posted shortly after at my blog.
- Import Alice’s public key:
$ gpg --import publickey-alice@proton.me.asc gpg: key <redacted>: public key "alice@proton.me <alice@proton.me>" imported gpg: Total number processed: 1 gpg: imported: 1 - Download the email
.emlfile and the signature$ ls signature.asc 'GPG Signing test.eml' 'GPG Signing test.eml' signature.asc -
Extract the message to verify from
.emlfileThis is where things get difficult. The downloaded email
*.emlhas a lots of unnedded information that needs to be discarded. I highly recommend that you make a copy of the email file because it does take a while to get used to.The content of the message starts after you see the following header (the hash will differ):
This is an OpenPGP/MIME signed message (RFC 4880 and 3156) --------7005887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69bc70aSo for instance, let’s look at the following file:
MIME-Version: 1.0 Content-Type: multipart/signed; protocol="application/pgp-signature"; micalg=pgp-sha512; boundary="------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415"; charset=utf-8 This is an OpenPGP/MIME signed message (RFC 4880 and 3156) --------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415 Content-Type: multipart/mixed;boundary=---------------------ff35159c3ebf11234dd954191b3141592Then the first line of the signed message is:
Content-Type: multipart/mixed;boundary=---------------------ff35159c3ebf11234dd954191b3141592Where the signed message ends is a scene of confusion. On the internet, there are many that says you to put everything between the first boundary and the second boundary into a new file. The boundary they are referring to is the line after
This is an OpenPGP/MIME signed message (RFC 4880 and 3156)which has the form----<hash>.--------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415 //email content --------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415Despite my many attempts, I had no success till I realized you have to delete all trailing new lines. One thing I notice is that the hash on the first line of the signed message is also the last line in the signed message.
Content-Type: multipart/mixed;boundary=---------------------ff35159c3ebf11234dd954191b3141592The first line of the signed file
The hash on the first line of the signed message is:
ff35159c3ebf11234dd954191b3141592so our file should also end with this hash.If our message looks something like this:
MIME-Version: 1.0 Content-Type: multipart/signed; protocol="application/pgp-signature"; micalg=pgp-sha512; boundary="------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415"; charset=utf-8 This is an OpenPGP/MIME signed message (RFC 4880 and 3156) --------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415 Content-Type: multipart/mixed;boundary=---------------------ff35159c3ebf11234dd954191b3141592 ... -----------------------ff35159c3ebf11234dd954191b3141592 Content-Type: application/pgp-keys; filename="publickey - alice@proton.me - <redacted>.asc"; name="publickey-alice@proton.me.asc" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="publickey-alice@proton.me.asc"; name="publickey - alice@proton.me - <redacted>.asc" ABCDEF0x4ZjZkeGxSL0xUABCDEFmltotlUR0ABCDEFWaABCDEFE9PQP9ABCDEFAABCDEFtLUVORCBABCED ABCDEFEABCDEFFWSBCTE9DSy0tLABCDE== -----------------------ff35159c3ebf11234dd954191b3141592-- --------3141887d7abcdefgbe09e18825fd164103abcdefgf8c40b59382649cd69b31415Then the signed message should be
Content-Type: multipart/mixed;boundary=---------------------ff35159c3ebf11234dd954191b3141592 ... -----------------------ff35159c3ebf11234dd954191b3141592 ... -----------------------ff35159c3ebf11234dd954191b3141592 Content-Type: application/pgp-keys; filename="publickey - alice@proton.me - <redacted>.asc"; name="publickey-alice@proton.me.asc" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="publickey-alice@proton.me.asc"; name="publickey - alice@proton.me - <redacted>.asc" ABCDEF0x4ZjZkeGxSL0xUABCDEFmltotlUR0ABCDEFWaABCDEFE9PQP9ABCDEFAABCDEFtLUVORCBABCED ABCDEFEABCDEFFWSBCTE9DSy0tLABCDE== -----------------------ff35159c3ebf11234dd954191b3141592-- -
Verify the signature:
gpg --verify signature.asc message.txt$ gpg --verify signature.asc message.txt gpg: Signature made Mon 07 Oct 2024 11:29:48 PM EDT gpg: using EDDSA key <redacted> gpg: Good signature from "alice@proton.me <alice@proton.me>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: <redacted>
In practice, no one verifies the digital signatures of emails manually. Any sane individual will utilize any email client that would automate the verification process for them. This was a quick preview of a blog post I will be writing in the next few days that will go into email signatures in more details with better explanations and diagrams.
[Preview] Half-Width and Full-Width Characters
October 6, 2024
Those of us who live and speak English will probably never think about how characters are encoded which is how characters such as the
very letters you see in the screen are represented by being given some number like 65 for ‘A’ in ASCII which takes 1 byte to be represented
such as a char in C.
I was not aware of the existence of full-width and half-width characters till the friend asked me to briefly explain the highlevel information about the difference in representing the characters. For those like me who weren’t aware that the Japanese mix between zenkaku (full-width) and hankaku (half-width) characters, look at the image below or visit this webpage: https://mailmate.jp/blog/half-width-full-width-hankaku-zenkaku-explained

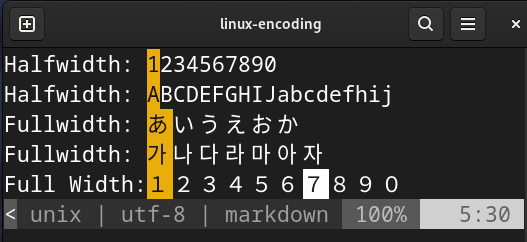
Based on the article I shared, half-width characters takes up 1 byte while full-width characters takes up 2 bytes (also can be called double byte character). I do believe this depends on the encoding used. For me, the most obvious distinction between half and full width characters is how much graphical space it consumes as evident from both the image above and below:

Full and Half Width encoded on UTF-8 as seen through Vim
While I have read and typed Korean during my younger years when I was forced to learn Korean, it never clicked to me how much space Korean
takes up graphically. It is obvious in hindsight but it was nonetheless interesting. Taking a look at the size and bytes encoding, we can
see that number 1 in UTF-8 encoding takes 1 and 3 bytes for half-width and full-width character repsectively
$ stat -c "%n,%s" -- halfwidth-utf8.txt fullwidth-utf8.txt
halfwidth-utf8.txt,1
fullwidth-utf8.txt,3
One confusion I had was understanding what the difference between UTF-8 and UTF-16 and the following excercise helped me understand this:
- UTF-8 encodes each character between 1-4 bytes
- UTF-16 encodes each characters between 2-4 bytes
UTF-8 and UTF-16 as you can tell are variable length meaning they take up more or less bytes depending on the character being encoded. We can
see this by comparing the number 1 arabic numeral v.s. 一:
$ stat -c "%n,%s" -- halfwidth-1.txt chinese-1.md
halfwidth-1.txt,1
chinese-1.md,3
In UTF-8, 1 takes up 1 byte which is unsurprising as ASCII has great advantage in UTF-8 compared to other Asian languages.
Note: Do not attempt to display UTF-16 encoded files on the terminal without changing your locale (or whatever it is called). It will not display nicely. Vim on my machine will automatically open the file as UTF-16LE.

Let’s inspect the contents of the files between Half character 1 and Full Byte Character 1 in HEX:
$ cat halfwidth-1.txt; echo ""; xxd halfwidth-1.txt; cat fullwidth-1.txt ; echo ""; xxd fullwidth-1.txt 1 00000000: 31 1 1 00000000: efbc 91 ...
As we can see, the half-width character 1 in UTF-8 is represented as 0x31 meaning only one byte would be required. However, a full-width
digit 1 is represented as 0xEFBC91. Now let’s compared this with UTF-16:
$ cat halfwidth-utf16.txt; echo ; xxd halfwidth-utf16.txt; cat fullwidth-utf16.txt; echo; xxd fullwidth-utf16.txt
1
00000000: 0031 .1
�
00000000: ff11 ..
Note: To view UTF-16 on VIM run on command mode (i.e. press esc to exit current mode and press : to enter command mode): e ++enc=utf-16be fullwidth-utf16.txt
As expected, UTF-16 represents code points in the upper range very well where we now see 1 (full-width 1) being represented with only 2 bytes unlike the 3 that was required in UTF-8.
Though the same cannot be said for code points in the lower range such as our half-width digit 1 which now takes 2 bytes by appending 0x00 to its hex representation.
I will be writing a more detailed look into encoding at my blog in the coming days. This is just a quick preview.
Mixing Number and String
September 18, 2024
A recent post has gotten somewhat popular on the web and is something many of us could
somewhat relate with. In the case of many including the author, the issue stems from how YAML treats strings and numbers. As a rule of
thumb, I would always suggest avoiding any potential confusion by always adding the quotes around a string to ensure the value is treated
as a string as intended. The crux of the post was how their Git commit inconveniently happened to be 556474e378 which is very rare
to obtain. Recall that scientific notation is in the form of \d+(\.\d+)?E-?\d+ such as 8.5E-10 to refer to 8.5 x 10-10.
The issue that one may encounter when mixing numbers and strings is that things can go very unexpected like the author did whereby
556474e378 was treated as 556474 x 10378. While I do not have any specific examples in mind when I have encountered such issues,
I definitely have encountered this issue before where I mixed up a string and a number and obtained an undesired behavior. However,
I do not think I ever encountered an issue where my numbers were interpreted as scientific notations.
`.` At The End of a URL
August 30, 2024
I recently learned that websites can be terminated with a . such as www.google.com. or https://neocities.org..
However, this does not work for all websites. I was skimming through Network for Dummies
during work and while it doesn’t cover anything useful for the work I am trying to do (if you have taken a network course before, don’t bother reading this book unless
you were bored like I was1), terminating a website with a . was a surprise.
The book states that If a domain name ends with a trailing dot, ..., and the domain name is said to be a fully qualified domain name (FQDN).
The difference between an absolute name (FQDN) and relative name is important when working with DNS and can cause an “internet outage” if
done incorrectly as one user on hackernews comments. Based on some article
(linked by a stackoverflow user), websites that fail
to handle . in their domain names are the ones who are in violation of RFC 1738 or at least not heeding
to its recommendations.
Notes:
1 While Network for Dummies was actually fun to read surprisingly due to the author’s writing style, it lacks technical depth which should come to no surprise.
Splitting Pdfs into Even and Odd Pages
August 28, 2024
During the winter break I have obtained an old Xerox XE88 Workstation Printer released in the year of 2000, the year where the media were worried about Y2K causing havok to our digital infrastructure which never came to the scale we all feared thankfully. Though of course a bug will eventually will creep and wreck havok(i.e. Crowdstrike Falcon Update). But I digress, using this printer was filled with frustration as it is a relic from the past that is not meant to be used in 2024. Firstly, the printer requires a parallel port which no modern computer comes equip with. I have to drag out my last surviving desktop from my childhood that originally came with Windows Me that we immediately switched to the glorious Windows XP that we all know, love and dearly miss. As it turns out a few months later after my first use of the printer, my PS/2 connected mouse stopped working. I do not know if the PS/2 port is broken or if my PS/2 mouse is broken. I did manage to find another PS/2 mouse but as it was water damaged from a basement leak a few years ago, there was little chance it would work. Without a mouse made this task much harder, but I digress.


Parallel Port
PS/2 Port typically found in desktops from the 90s
Placing aside the hardware struggles to operate such printer in 2024, the printer does not have duplex printing so I had run commands on my pdfs on my Linux machine before transferring the files to my Windows XP machine (thankfully there are USB ports on this desktop that work or else I would have to dust off my 3.5 inch floppy disks and CDs). To split pdfs into even and odd pages turns out to be a very simple command:
pdftk A="${file}" cat Aodd output "${file}-odd.pdf"
pdftk A="${file}" cat Aeven output "${file}-even.pdf"As I am printing a bunch of papers on Trusted Computing, I needed to split a lot of PDFs so this task can get quite tedious so I wrote a simple shell script:
for file in *pdf; do
pdftk A="${file}" cat Aodd output "${file}-odd.pdf"
pdftk A="${file}" cat Aeven output "${file}-even.pdf"
doneExecuting Script Loophole
August 28, 2024
I recently came across an article discussing an attempt to close a loophole bypassing the normal execution permission bit. Exploiting a program suid and euid to gain high privilige is a commonly known technique called privilege escalation. This article does not cover this but it introduces a flaw in the current way Linux handles the execution of scripts. I do not know why privilige escalation came to my mind but as I usually write nonesensical things anyways, I shall keep it here for now. The article gives a neat example where a script does not have execution bit but is still executable by invoking the script via an interpreter.
$ ls -l evil-script.py
-rw-r--r--. 1 zaku zaku 86 Aug 28 00:20 evil-script.py
$ ./evil-script.py
bash: ./evil-script.py: Permission denied
$ python3 evil-script.py
Evil script has been invoked. Terror shall fill this land
As you can see, the script has no execute bit set. However, the script is still executable by feeding the script to the interpreter.
I have never considered this a security loophole but after reading the article, I realized there are some concerns of allowing scripts
to be executable bypassing the file’s permission. I have always made the habit of running many of the interpreted scripts non-executable
and fed them to the interpreter due to laziness (I know it’s a one time thing to set the execute bit but I am just lazy to run chmod).
The article covers some promising approaches so I do expect a solution to be merged into the kernel sometime in the near future which will force me to change my habits once the interpreters make the change. Though if interpreters do make this patch, I do expect quite a few production and CI/CD servers to be impacted as there will always be someone like me who are lazy to set the execute bit on our scripts.
One benefit of closing this loophole is to force users to deliberately make the conscious choice to set the execute bit similar to how we have to set the flatpaks we download as executables (at least from my personal experience) before we can execute the flatpaks.
Replacing main()
August 24, 2024
Any beginner C programmer will know that the first function executed in any program is the main() function. However, that is not the entire
truth. Just like how we have learned the Bohr and Lewis diagrams in Chemistry in Highschool, this is an oversimplification. From my knowledge,
the first function executed once the loader runs in a binary is _start().
Without going into any details, we can replace main() with another function such as foo() (sorry for the lack of creativity).
#include <stdio.h>
#include <stdlib.h>
int foo() {
printf("Called foo\n");
exit(0);
}
int main() {
printf("Called main\n");
return 0;
}If we compile with -e <entry> where <entry> is the name of the function replacing main(), we can see the following results:
$ gcc foo.c -e foo
$ ./a.out
Called foo
We can also observe from objdump and nm to see where the start_address of the C code is (here I am making a distinction between the
first entry point of the C code and the binary).
$ objdump -f ./a.out | grep start
start address 0x0000000000401136
$ nm ./a.out | grep foo
0000000000401136 T fooFew Notes
- You must define
main()even if it’s not going to be used. CPP Reference states this explicitly:Every C program coded to run in a hosted execution environment contains the definition (not the prototype) of a function named main, which is the designated start of the program.
Neglecting to define
mainresults in an error like the following:$ gcc foo.c /usr/bin/ld: /usr/lib/gcc/x86_64-redhat-linux/14/../../../../lib64/crt1.o: in function `_start': (.text+0x1b): undefined reference to `main' collect2: error: ld returned 1 exit status - The C program entry must call
exit()to terminate if it is notmain()or else a segfault will occur$ ./a.out Called foo Segmentation fault (core dumped)a backtrace via gdb won’t give much information as to why. Probably best to consult with glibc. Essentially it is likely due to the fact that
_startis not a function that returns in the stack. It callsexitto terminate the program which probably does some cleaning viaatexitand set the exit status$?to some value.(gdb) bt #0 0x0000000000000001 in ?? () #1 0x00007fffffffdd46 in ?? () #2 0x0000000000000000 in ?? ()
Random Links for later Research
- https://vishalchovatiya.com/posts/crt-run-time-before-starting-main/
- https://www.gnu.org/software/hurd/glibc/startup.html
- https://stackoverflow.com/questions/63543127/return-values-in-main-vs-start
Editing GIFS and Creating 88x31 Buttons
August 18, 2024
Lately I have been learning how to edit GIFS and it is painstaking difficult to remove a background from a GIF without using an
AI tool, especially when the image has over 70 frames. There is likely an easier way to edit GIFs but I had to manually edit over 50
frames, erasing the clouds from a GIF using the eraser tool frame by frame which took some time to finish.
Original:
Result:

However, if you are not editing a GIF but rather trying to incorporate the GIF into your 88x31 buttons, it turns out to be quite simple. Following the instructions from a video on Youtube, I managed to create a few simple 88x31 buttons that have features cats, coffee, and the two programs I am or finished studying (i.e. doing a 2nd degree):



To resize the gifs, I used ezgif resize tool to set the height to be 31px since I didn’t know how to resize GIFs on GIMP as it would open a bunch of layers. I guess I could have used ffmpeg but using an online tool is just more convenient and easier. I do wonder if there are other standard anti-pixel button sizes aside from 80x15 pixels because a height of 31 pixels is quite limiting. It’s amazing what the community has been able to do with such limiting number of pixels.




For instance, the Bash button I have made has the subtitle “THE BOURNE-AGAIN SHELL” which is very hard to make out. I am assuming the standard practice is to render the button as a GIF and display the text on the next frame. That way users would be able to see the full-text.
multiple definition of `variable` ... first defined here
August 10, 2024
Randomly I decided to compile some old projects I worked on and I was surprised to see a few compilation errors in an assembler I wrote years back. As it has been many years since I last touched most of the projects I looked at, I was pleased to see the compiler catching obvious mistakes I had made in the past. Though this did come to a surprise as to why the compiler I used years ago never complained such obvious mistakes. The solution and reason for the last compilation error was not immediate to me:
$ make
gcc -o assembler assembler.c symbol_table.c parser.c -fsanitize=address -lasan
/usr/bin/ld: /tmp/cc1MoBol.o:(.bss+0x0): multiple definition of `table'; /tmp/cc0B4XxW.o:(.bss+0x0): first defined here
/usr/bin/ld: /tmp/cc1MoBol.o:(.bss+0x81): multiple definition of `__odr_asan.table'; /tmp/cc0B4XxW.o:(.bss+0x40): first defined hereAt first I thought I may had made a stupid mistake and defined the struct called table twice but all I could find was symbol_table.h, the file that declared the variable,
being included by assembler.c and parser.c. This led to the conclusion there must have been a compiler behavioral change between GCC 9 and
GCC 14. After a quick googling and going through going through the Release Notes, it turns out that starting from
GCC 10, GCC now defaults to -fno-common:
GCC now defaults to -fno-common. As a result, global variable accesses are more efficient on various targets. In C, global variables with multiple tentative definitions now result in linker errors. With -fcommon such definitions are silently merged during linking.
In the Porting to GCC 10 webpage, the developers of GCC notes:
A common mistake in C is omitting extern when declaring a global variable in a header file. If the header is included by several files it results in multiple definitions of the same variable
To resolve this issue, one can either silently ignore their mistake and compile with -fcommon or to correctly declare the global variable with the extern keyword.
Delusional Dream of a OpenPower Framework Laptop
August 4, 2024
Framework is a company that makes modular and repairable laptops that has captured the interests of tech enthusiasts over the past 4 years. Currently Framework laptops are limited to x86-64 architecture supporting Intel and later AMD CPUs in 2023. Although Framework laptops are not entirely open source, they have open source a decent chunk of their work from my understanding and which allows third party development of components and makes partnership possible for other companies such as DeepComputing to release a mainboard that runs a RISC-V CPU . While the new mainboard will not be usable for everyday applications, it is a step forward to a more open ecosystem and this is an exciting step for both Framework, RISC-V and the broader open-advocate community. This announcement makes me wonder the possibility of OpenPower running on a Framework laptop. Similarly to RISC-V, there isn’t an easily accessible way to obtain a consumer product running on OpenPower (aside from Raptor Computing with their extremely expensive machines). There is the PowerPC Notebook project ran by a group of volunteers who are trying to develop an open source PowerPC notebook to the hands of hobbyists. It would be interesting if OpenPower community could also partner with Framework to develop a mainboard once the project is complete and the software is more matured. However, this would be a difficult step as there is no dedicated company like DeepComputing that will pour resources into making this happen. The interest into OpenPower is low and overshadowed by the wider industry interest in expanding the ARM and RISC-V architecture to consumers. IBM made a huge mistake in open sourcing the POWER architecture too late. But one could always dream (even if it’s delusional) :D
2024 Update
August 4, 2024
Website
In the past year I have been very lazy as evident with my lack of activity on my personal blog. I'm now trying to pick up blogging again. It's hard to believe that it's been almost an entire year since I created this neocity site, which has almost 0 updates since. I've been thinking about how to use this site since I already have a blog on GitHub Pages. Honestly, I forgot this corner existed, and it’s been bothering me that I couldn’t write my random, nonsensical thoughts because my main blog wouldn’t be a suitable medium until now. So, I’ve decided that this corner will be a microblog where I can share random articles and thoughts. A microblog is different from a regular blog in that the content is much shorter. This space will allow me to quickly jot down something random. I hope that a collection of these random posts will evolve into a blog post or spark an idea for my final year thesis or project.
How are my studies going?
I’m still studying Mathematics, but I’ve lost much of my initial interest in the field after taking a few third-year courses.
I ended up taking fewer Math courses, which puts my ability to graduate on time at risk.
Listening to lectures and reading about abstract groups and rings made me really miss programming and computer science.
 Despite this, there were still some Math courses I enjoyed, such as Combinatorics and Real Analysis.
However, I didn’t last long in the follow-up Real Analysis courses that covered Stone-Weierstrass and Commutative C* Algebra.
Feeling tired of abstract Mathematics, I decided to take a break and pursue an internship at a telecommunications enterprise.
Despite this, there were still some Math courses I enjoyed, such as Combinatorics and Real Analysis.
However, I didn’t last long in the follow-up Real Analysis courses that covered Stone-Weierstrass and Commutative C* Algebra.
Feeling tired of abstract Mathematics, I decided to take a break and pursue an internship at a telecommunications enterprise.
 What am I doing Now?
What am I doing Now?As mentioned, I am currently doing a year-long internship with a telecommunications enterprise. Although the job isn't very exciting, it's a welcome break from Mathematics. This would typically be a great chance to catch up on my Computer Science studies by delving into textbooks and online resources, but I’ve been quite lazy. Instead, I've been focusing on learning French, a language I've always wanted to master. I started learning French in elementary school, as it’s a requirement in Canada. While it might make more sense to learn my mother tongue, I’m opting to learn French, which might seem confusing to some. For context, I don't have an English name and was born in some Asian country but I am unable to communicate with others in my mother tongue.