
MicroBlog 2025 Edition
Continuing on from last year, here is a dump of all the microblogs I have posted in 2025 on neocities
While my microblog isn’t exactly short, it is definitely shorter than my typical technical blog posts and a bit more random. You may have noticed the new addition to the site that links to my microblog. This gets more frequent updates than the blog due to the nature, depth, and length of the posts. I am still debating if I should start converging the two sites together just for convenience sakes. Though that would mean the site will become more chaotic and random as a result.
You can visit my microblog if you are interested: Random Bits
Complete List
- [2025-12-11] The Unintended Consequence of Replacing CRLF (\r\n) to LF (\n) on PNG Images
- [2025-11-23] Braille in Pokémon Sapphire and Ruby Game and Manga
- [2025-11-21] Firefox - MP4 Cannot be Decoded
- [2025-11-18] Anime and Manga Tech Gallery
- [2025-11-18] Fedora 43: Random Request to Access Macbook Pro Microphone
- [2025-11-14] Random Photos
- [2025-11-08] How Linux Executes Executable Scripts
- [2025-10-31] Hangul - Unicode Visualiser
- [2025-10-06] UTF-8 Explained Simply - The Best Video on UTF-8
- [2025-10-06] Render Archaic Hirigana
- [2025-10-03] Migrating Away Github: One Small Step To Migrate Away From US BigTech
- [2025-10-02] Binary Dump via GDB
- [2025-08-27] Gundam With Decent Portrayal of Code
- [2025-07-24] Incorrect Translation of a Math Problem in a Manga
- [2025-07-23] Rational Inequality - Consider if x is negative
- [2025-07-04] The Issue With Default in Switch Statements with Enums
- [2025-05-24] 2025 Update
- [2025-05-06] DuoLingo Dynamic Icons on Android
- [2025-04-14] Behavior of Square Roots When x is between 0 and 1
- [2025-04-08] 4 is less than 0 apparently according to US Trade Representative
- [2025-03-16] Row Major v.s Column Major: A look into Spatial Locality, TLB and Cache Misses
- [2025-03-07] The Bit Size of the Resulting Matrix
- [2025-03-07] Compiling and Running AARCH64 on x86-64 (amd64)
- [2025-02-23] top and Kernel Threads
- [2025-02-11] this: the implicit parameter in OOP
- [2025-01-28] Software Version Numbers are Weird
- [2025-01-23] view is just vim in disguise
- [2025-01-21] My Thoughts on the Future of Firefox
- [2025-01-15] The Sign of Char in ARM
- [2025-01-04] A First Glance at Raspberry Pi 4 Running QNX 8.0
The Unintended Consequence of Replacing CRLF (\r\n) to LF (\n) on PNG Images
December 11, 2025
Today there was a PR at work that tried to address the issue of engineers submitting code with DOS (Window) end of line (EOL) to the codebase.
Background (Skip if you are a Programmer)
\r and \n are what we call control characters,
non-printable characters that have effects to data and devices. For instance, \a will ring a bell, \n (line feed) will cause the cursor to go to the next line and \r (carriage return)
causes the cursor to return to the first character in the same line.
DOS (Microsoft’s text-based OS) uses \r\n to indicate an end of line (which we commonly refer to as CRLF) meanwhile, UNIX and its variants and sucessors use \n to indicate the end of file (commonly
refer to as LF or newline in layman terms). CRLF notation makes more sense from a historical point of view (i.e. teletype and typewriters) but it also takes unnecessarily an extra character.
Anyhow, long story short, I noticed that the PR and subsequent PRs relating to convert DOS to UNIX file format broke PNG since the first 8 Bytes of all PNG (the header, also called the magic number)
contains 0D 0A (CR LF):
89 50 4E 47 0D 0A 1A 0A
Use xxd or hexdump on any PNG file and you will discover this yourself..
$ convert -size 32x32 xc:white empty.png
$ xxd -l 8 empty.png | grep 0d0a
00000000: 8950 4e47 0d0a 1a0a .PNG....
Converting to UNIX style causes the PNG file to no longer be an image:
$ file empty.png
empty.png: PNG image data, 32 x 32, 1-bit grayscale, non-interlaced
$ dos2unix -f empty.png
dos2unix: conversion du fichier empty.png au format Unix…
$ file empty.png
empty.png: data
Braille in Pokémon Sapphire and Ruby Game and Manga
November 23, 2025
Pokémon Crystal was the first to introduce symbols or glyphs for players to decode according to my research. [1] Thankfully the Unknowns ressemble the English or the latin alphabet so the task to decode the ruins was feasible for children. However, in generation III, in the Hoenn region, decoding the ruins has gotten much more tricker with their use of Braille.
Braille is for the blind and the visual impaired and therefore would likely not be able to play the game. So the task of decoding the ruins would be a great challenge.
Reading the manga, Pokémon: La Grande Aventure - Rubis et Saphir, there’s a single black page with random white dots. Confused I did some research and found out it was braille.

Random Braille at the end of chapter 21 (or 201)
Since then, I noticed that each chapter would contain braille. This got me curious as to what it was. However, I had no success till I realized the braille was not localized and remained in Japanese braille. The game were localised though:
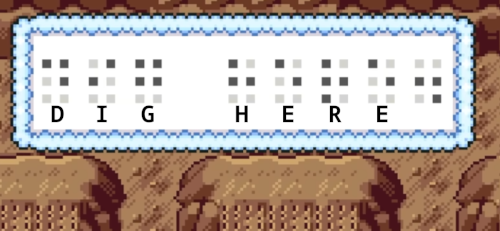

WARNING: I know the neocities community has a distaste for AI but it has been used to aid in the translation
Through the power of vibe-coding on Gemini, I was able to create a primitive translator:
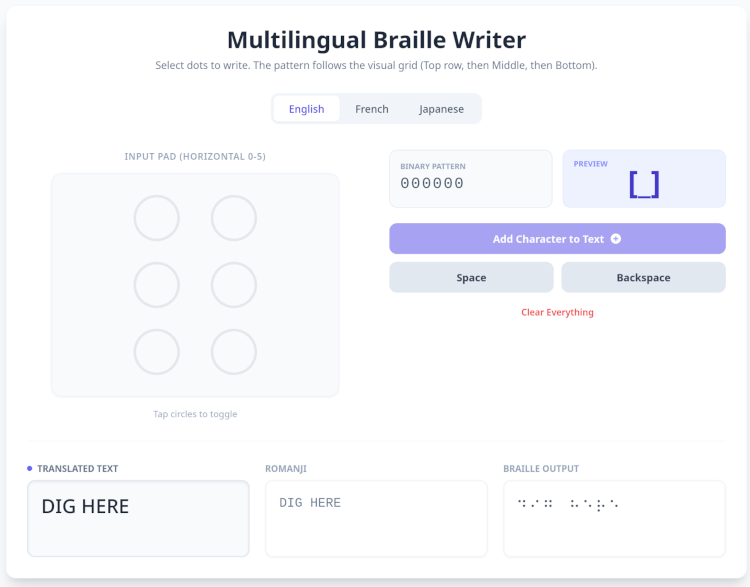
Screenshot from a vibe-coded braille translator
This tool comes in handy for Japanese as it’s a language I am unfamiliar with and hence why I needed this braille translator.

Japanese braille to Kana support
Failed Attempts to use AI to translate braille
AI (Gemini and ChatGPT) fails to translate Japanese braille into English. I provided both LLMs the braille in unicode and a screenshot of the braille and the results were disappointing. Gemini was convinced the braille was in English meanwhile Chatgpt faired better recognizing it was not possible for the braille to English. Furthermore, ChatGPT stated it could not infer the message from the unicode but when provided with an image of the braille, it incorrectly translate the message to `ガラスのつばさ` or `Wings of Glass`. As you may notice, the word appears to be shorter than what it should be, that i is because ChatGPT deleted them by justifying they weren't standard Japanese words.
The resulting kana that was translatable on the vibe-coded translator was: おやこのたたかい あれかんえ つこいく
I did skip one braille pattern during the translation as the vibe-coded translator did not recognise what it was so it’s not a direct translation but it should be good enough for my use case.
The English translation is Parent and child battles. One important note about this page, this page appears at the end of volume 16 which I did not realize since the French translation is in an omnibus (i.e. multiple volumes are packed into one large collection).
According to Bulbpedia is titled 親子の戦い or in English Battle Between Father and Son.

Translation provided by j-talk
 In each chapter, there is a corresponding braille which Bulbapedia conveniently provides.
It was only after I gave up trying to decode and translate the braille, that I realized there was no relationship between the titles in both English (ChunYi) and French editions.
In a few weeks, I will be visiting my family so I should be able to determine if this is the case with the Korean edition as well since I do have a copy of the manga.
In each chapter, there is a corresponding braille which Bulbapedia conveniently provides.
It was only after I gave up trying to decode and translate the braille, that I realized there was no relationship between the titles in both English (ChunYi) and French editions.
In a few weeks, I will be visiting my family so I should be able to determine if this is the case with the Korean edition as well since I do have a copy of the manga.
Note: Some editions of the English translations apparently has better subtitles that better reflects the braille:
It is subtitled Restarting (Japanese: 決意の再出発 Deciding to Restart) in the VIZ Media translation and Setting Off Again in the Chuang Yi translation.
Description from bulbapedia
The vibe-coded braille to kana translator outputted: けつい の さい す゛ はつ のまき which when plugging into Chatgpt gives the following after prompting it to translate it into
English that is natural sounding:
-
“The Chapter of Determination” (most natural, common in manga)
決意の巻(けついのまき)
-
“The Beginning of Determination”
決意の初(はつ)めの巻
-
“The Birth of Determination”
決意の発(はつ)章
-
“The Size of Determination” (literal but natural)
If you actually want “size” (サイズ):
決意のサイズの巻
-
“Determination: First Chapter”
決意・第一章(だいいっしょう)
The actual answer is the following:

or officially:
- VIZ:
Mixing It Up with Magcargo - Restarting - ChuangYi:
VS Magcargo - Setting Off Again - Original:
VS マグカルゴ - 決意の再出発
Conclusion
The mysterious braille that the author dedicated an entire page to was simply Parent and child battles. Each chapter subtitle (if it exists in your edition) has a corresponding braille counterpart.
The braille in the English and French translation has not been localised.
Update: 2026-01-01

Chapter 239 title page in French and Korean
As I suspected, the Korean translation did not bother localizing the braille.
As a bonus, here are some questionable translations I found thus far:


There are more in Chapter 233 but I figured there could be some cultural context I am missing as an anglophone so I shall refrain from stating it’s a mistranslation.
[1] Based on bulbapedia and from my personal recollections, there were no messages to decode in the original Gold and Silver editions
Firefox - MP4 Cannot be Decoded
November 21, 2025
One constant issue I have with Firefox is the instability of playing videos outside of Youtube. Often when watching anime online, I would often encounter issues where skipping even a second would cause the video to stop playing. Hence why I have mention in my FAQ that I use Brave, a privacy-focused chromium browser, to stream anime.
While making my gallery featuring retro tech on neocities, I encountered a similar issue. Firefox was unable to loop a MP4 video I uploaded. Though Brave unsurprisingly could.
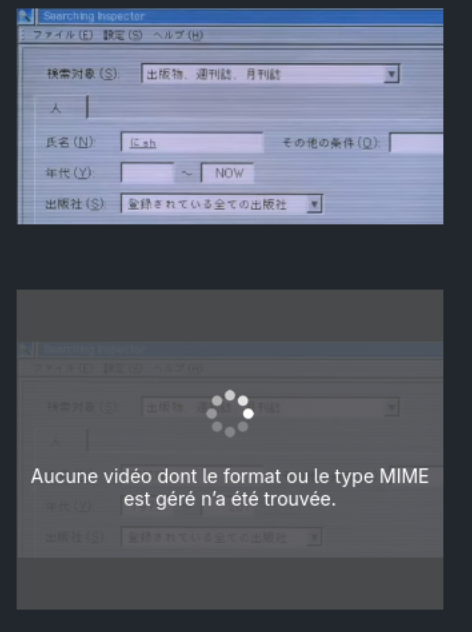
The simple solution to the problem was to convert the MP4 video into webm, an open and royalty-free media format which is the image you see on the top meanwhile the video on the bottom was encoded in HEVC (H.265) via ffmpeg (not ffmpeg-free).
I was under the impression that Firefox supported HEVC but it turns out there are only limited support.
Based on the Error displayed on the video and Firefox complaining decoding error on the Web conole, I knew Firefox was missing some type of decoder to play my MP4 file.

Placing about:support#media on the Firefox address bar reveals everything I needed to know:
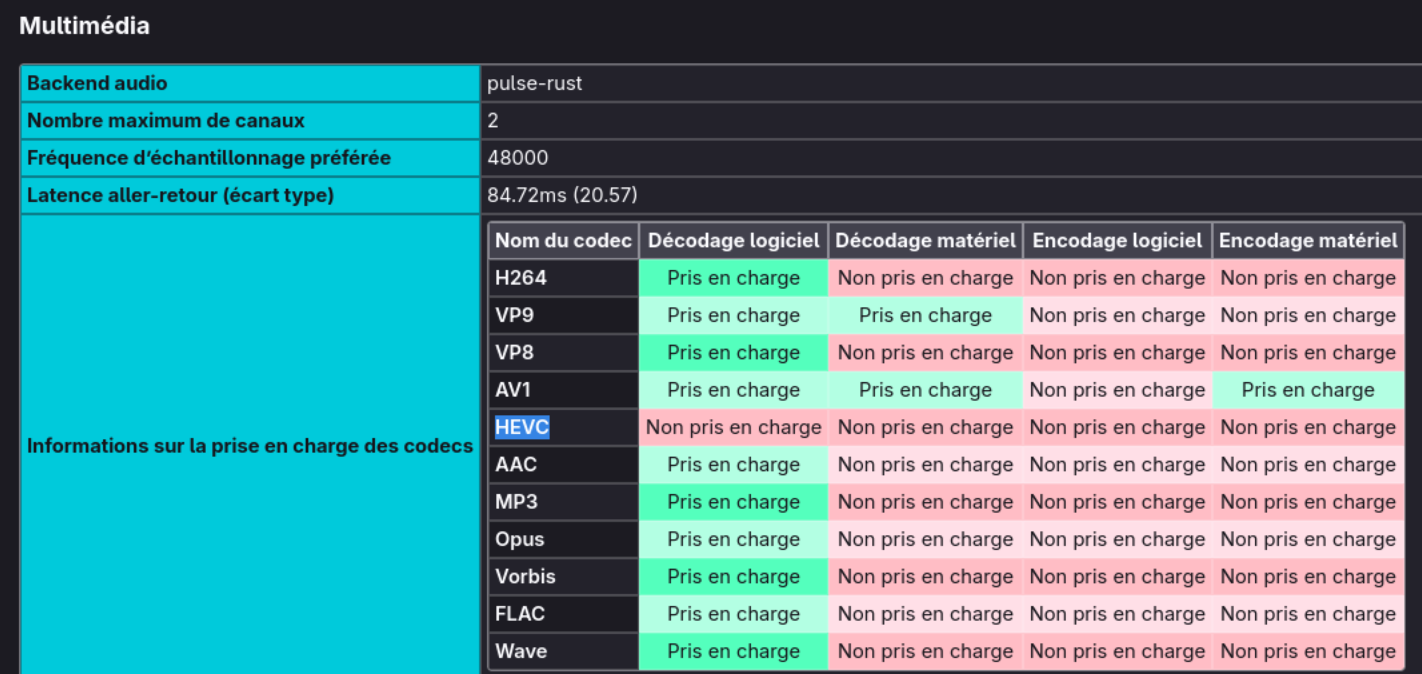
Despite having HEVC en/de-coders on my Linux system, I needed to enabled them via Firefox configuration (about:config):
media.hevc.enableddom.media.webcodecs.h265.enabled
However, I opted to convert my MP4 file into webm to open access to all visitors.
HEVC is a patented code which based on Wikipedia only waives royalties on software-only implementations (and cannot be bundled with hardware).

Note: “Prise en charge” is “Supported” and “Décodage logiciel” is “Software Decoder” in English
UPDATE: The day I published this blog, I woke up to see an article about HVEC popping in my hackernews feed: HP and Dell disable HEVC support built into their laptops’ CPUs . Originally I was under the impression that CPU manufacturers such as AMD and Intel would be responsible to pay those fees but according to Ars Technica, it is not known if they indeed do. Tom’s Hardware reveals that chipmakers (at least in the GPU side) do have to pay a license fee to implement the feature in silicon. But it also reveals that to enable hardware decoding on the device leve, OEMs must also pay the fee. Therefore it would seem that HP and DELL will be disabling this capability on the software side (either on the driver or fireware level) if this logic applies for CPU as well. Considering the volume of CPUs DELL and HP purchase from AMD and Intel, I do think it could be possible for them to also request to fuse the capability off in silicon (though unlikely). As Tom’s Hardware notes, this is typically not done on the GPU so if we assume the same logic applies to CPUs, it is likely disabled on the software side.
Note: Not a support on Neocities so the video is hosted on codeberg
Anime and Manga Tech Gallery
November 18, 2025
For years, I always wanted to create a webpage with a collection of images from manga and anime that featured code or computers. I did amass a large collection but loss many of them over the years and the ones I do still have, I no longer remember where it is from.
You can view the galllery under /galllery
Watching Patlabor Movie 3 (ya I know it’s not good), I decided to start a new collection from scratch. Here are some notable snippets:

The movie was released in 2002, around the year my family got our first set of desktops that I grew up with. As typical for this time period, the desktop features a CD drive (not DVD) and a floppy disk drive.

From a side angle, it becomes clear that the mouse connector is likely a PS/2 connector and not USB (also typical during this timeframe).
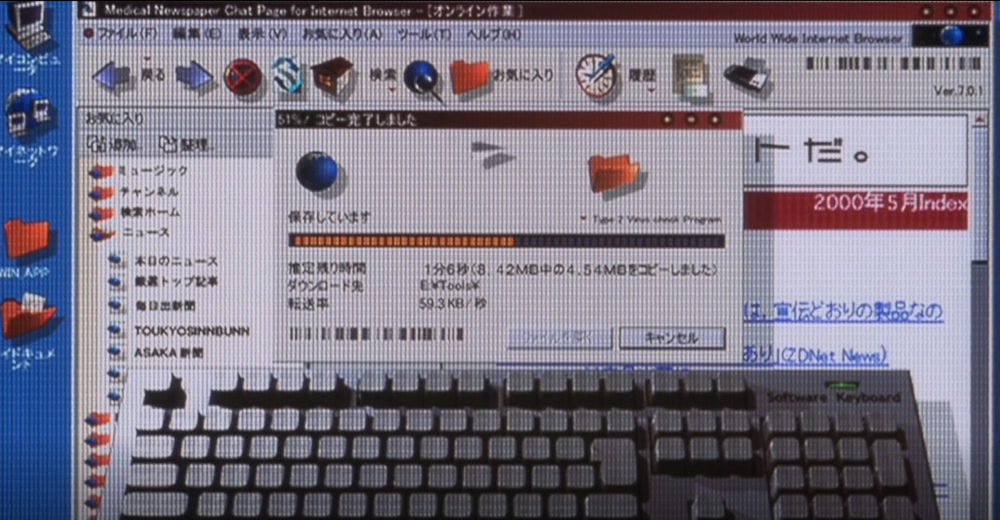
A retro view of downloading a file from the internet back in the day. The blocky windows, the use of large icons and download animations suggests that this is featuring Windows 95 or Windows Me. Though the circular window options (e.g. the minimize, expand, and close buttons) being circular makes it hard to tell the browser being feature. It could be Netscape or Internet Explorer (IE). I am going for Internet Explorer due to the fact that Netspace popularity severely declined in the late 90s. The version number does not match IE version at time the movie was released. It would have been likely IE 4 or IE 5 that is being featured but perhaps there was a Japanese web browser during this time period that I am not aware of that would better match this.
A feature now lost in time, the iconic zoom magnifying glass. I am not sure when web browsers started to phase out this feature, I totally forgot it even existed. Looking at demos for Internet Explorer 6, the picture resizing tool is quite different from what I recalled. Perhaps this feature died off much earlier than I thought.
Bonus: I found a nice webpage that features the looks of various softwares at different period of time.

The style of placing the monitor above the horizontal desktop tower is definitely the product of the 80s or the early 90s. Monitors in the were typically fat back then, even during the early 2000s as LCD displays were expensive compared to their CRT counterparts.
Bonus: Japanese Computers

A classical VHS cover along with an audio casette tape that were popular in the 80s and the 90s. Not sure if it’s the art, but I recall casette tapes being much slimmer than portrayed in the anime. Perhaps this is not an audio casette but rather a compact VHS (VHS-C used in camcorders. I simply assumed it was an audio casette tape since there would be no need for a VHS and it is later featured for audio usage in the movie. Though I could have recalled this incorrectly.
Note: My memory is very fuzzy when it comes to tech from the 80s and 90s as I grew up in the 2000s so I only had limited interaction with these technologies.

This is from the webtoon, I Became the Villain the Hero Is Obsessed With, featuring the output of the top command.
Fedora 43: Random Request to Access Macbook Pro Microphone
November 18, 2025
Fedora 43 was released in October 28 and my only gripe against this update is their inclusion of ROAP, some feature to connect to Apple devices. It was honestly annoying because my microphone would stop working once the video platform demands if I wish to connect to someone’s Macbook nearby. And this happens often during classes so I often had to re-enter the room to resolve my microphone issue.
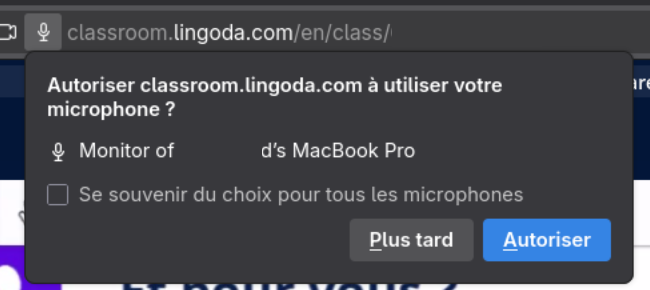
Within my audio settings in the quick access menu on the top right of GNOME Desktop shows various Apple devices that can be used for audio output:
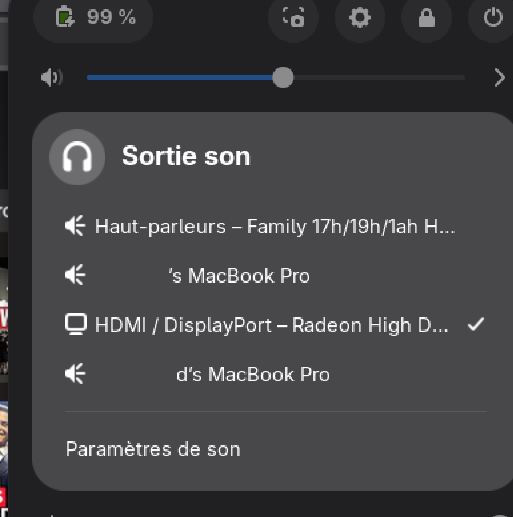
It is not clear to me if Fedora purposely included this Pipewire module or it came packaged in the Pipewire version they selected. Regardless, it’s plain annoying. While not the same, others appear
to have encountered the same issues. Following another approach from Reddit,
I at least have gotten their weird Microphone request prompts. Though I can still Apple devices as potential audio outputs, I can live with Apple polluting my audio settings. The solution is to delete
the offending package pipewire-config-roap
Random Photos
November 14, 2025
Nothing technical, just some random photos I took that I found on my phone.

It snowed recently in the city I currently moved into. Though it quickly melted. It’s definitely a lot warmer here compared to where I am from.

Disassembling my laptop because I spilled coffee over it … nothing got damaged thankfully. Though if any components got damaged, it would be easy to repair (#Framework). Reminds me how I once destroyed my Lenovo P50 workstation years ago … the company did not give me an expensive laptop after that incident.

While I don’t use my pull-up bar as much as I should, it makes a good dry rack.

Snow in my “home city”, apparently this was in April based on the name of the image … the first real winter in a while. Winters in Canada, at least in my homecity, has been quite warm over the past few years unfortunately. Hopefully, we will see some normal winter this year.

I spoiled myself last month with Lego. I have not touched lego in over 15 years … I sure am old … The kit impressed me a lot.

One of my favorite PS1 games and games in general (I do not play much video games), Lunar the Silver Star and Lunar Eternal Blue, on the Switch. Luckily the game I preordered came just before I moved to another city for my internship. Great game, I hope they make a remake of Mana Khemia Student of Al-Revis. It seems like they made a remake of Final Fantasy Tatics recently :)
This is the game that got me into JRPG, I loved the dialogue and the storyline a lot. What is great about Switch games is that you can change the language easily so this was my first game all in French.

My Pokémon Gameboy Color collection. Most of the games were a Highschool birthday gift from my father. I grew up with Pokémon Yellow and Silver which explains why I have two copies of them. Pokémon Crystal is in Japanese so I never bothered playing it. Growing up, my Dad would periodically mail to my brother and I Japanese magazines and electronic kits. Though that never motived any of us to learn Japanese. Though I think my brother did learn a bit during the pandemic but stopped when he started his Masters. (Not from a Japanese family to dispell any potential misunderstanding).
Also featured in the photo is my Pikachu pencil holder (the one in front of my tamagotchi) and some random Maplestory tokens that I am not sure what they are for. There are also some Hanafuda cards that you may have seen in Summer Wars. I forgot how to play the game. My grandmother would often play with Hanafuda cards alone, not sure what game it was. There is also a Digivice that I used to play with, I think it originally belonged to my sister. In kindergarten, I had the OG digivice but I have very little recollection of it aside from recalling of its existence. Too bad I no longer have my Golden Burger King Pokémon Cards, my mother gave it to some kid as punishment for not cleaning my room along with a bunch of my other toys. There is also Laputa Poker Cards in the background if you were wondering what anime that is from. Funny enough, I don’t think I ever watched Laputa in English just like how I never watched Totoro in English (no subtitles either) so I probably never understood the story properly.
{kind=link}

An Elder Scroll t-shirt I won at one of the places I worked at. Unfortunately it’s 2XL, way too large for me. I have a knack winning t-shirts way too large for me at company events including a Raptors in 2019, the year the Raptors won the NBA Championship. This will probably end up as a gift or a cushion for my fragile items. On that day, I learned that Skyrim is part of Elder Scrolls. I am ignorant when it comes to video games as I don’t play them often.

A sticker I received on AMD’s 40th anniversary in Canada. It’s actually the 40th anniversary of ATI’s founding, a Canadian semiconductor company that specialized in developing GPUs which AMD bought. That is how AMD entered the GPU market. The Canadian office does a lot of CPU and GPU related design but I don’t think most Canadians know this.

An Ericsson branded car roaming around the community near their office. Ericsson is a Swedish company that is currently dominating the 5G market (if we disclude Huawei). Nokia and Huawei is within 10 mins walking distance from the Ericsson building I used to intern at. Canada used to be the best in Telecommunications with the likes of Nortel and Blackberry dominating the telecommunication and handphone market. Though poor management decisions caused the two to fall … Blackberry still exists but they pivoted markets. As for Nortel, as much as some may say Huawei stole their IP, it was ultimately mismanagement that brought down Nortel, and not from Chinese espion. Fun fact, Nortel HQ became the HQ for the Department of National Defense and it took the military some time removing all the “bugs” from the building. Another timbit, Nortel execs knew of Chinese espionage but did not care at all.
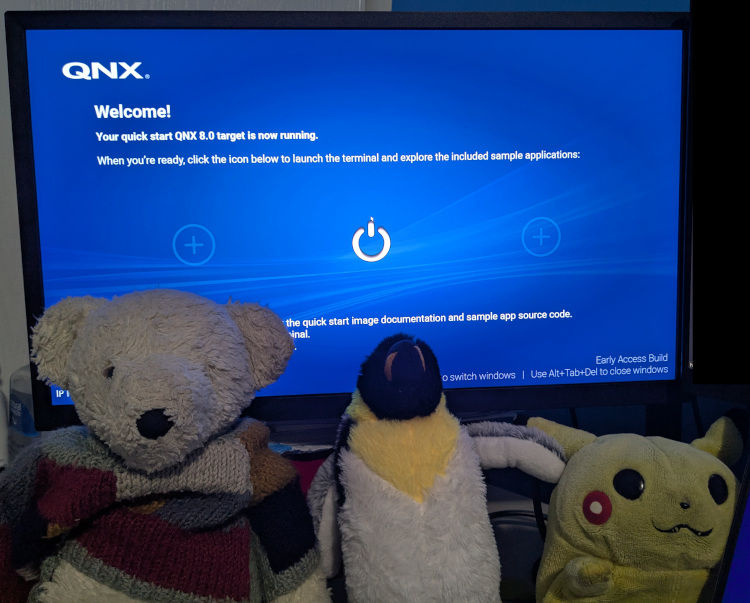
Continuing on the theme of companies I formerly interned at, here is QNX 8.0 running on a Raspberry PI. QNX Is a Real-time Operating System (RTOS) that was started in my “neighborhood” (not sure what to call it as it’s no longer considered a city but a suburb of a larger city). It’s primarily used in cars but it can be used in any safety critical devices such as in medical devices and in rockets (though I am not entirely sure of how widely adopted it is within the space industry). It’s one of the three widely-used Microkernels (from what I know), the other being Minix installed in every Intel chip and Apple. Apple has adopted some variant of L4 Microkernel OS for their ARM secure enclave and it also appears that SeL4 is used in many places as well so my statement about QNX may be false. There’s also WindRiver’s VxWorks. I never looked at the figures so my claim about QNX being one of the 3 most-used Microkernels could be entirely false.

Now that I moved closer to the city where I did my studies in Computer Science years ago, I decided to take a tour and see what has changed. It seems like there are a lot more robotic arms now. In my final year, I was one of the first students to take robotics in the department of Computer Science (officially called the Department of Math, Statistics, and Computer Science), and we had no robotic arms for use. It was all simulation but that might have been for the best. I definitely would have broken an arm or two with my terrible code and calculations.

Not sure what the trend was but when I visited my alma mater in the spring, the Computer Science profs have been posting Pokémon cards on their doors with cute name-tags.

At my current university, all the buildings are connected by tunnels, allowing students to avoid the snow during Winter. This is the old Math Society’s mural in the tunnel proudly featuring Tux the Linux Penguin. There is now a new Math Society mural but it looks like some ugly jail cell. My friends and I are clearly not artists …. Unfortunately, I don’t have photos of the new mural but perhaps I will take a picture when I return back to finish my final year of undergrad (hopefully). Trust me, you will be disappointed if you were to see the new mural. The new mural does not have Tux the Linux Penguin unfortunately due to my lack of skills. I was notified that if I don’t visit the university before I move, there would be no reference to Linux in the new mural. Therefore, I had to come and write “LINUX” in large font to overpower all the random math equations on the wall.
p.s. I ain’t going to verify if the first 4500 digits of PI was actually written correctly but feel free to verify yourself.

A friend doing graduate studies in Linguistics recently went to Japan in the summer and mailed me this postcard from there. I guess he was in Japan for a while. I got to know him from my Mathematics courses as he was originally a Mathematics student who had a well-diverse interest in science, music and languages.

While I rarely eat out due to costs, I found an anime styled drawing at McDonald’s kiosk which was surprising.
How Linux Executes Executable Scripts
November 8, 2025
One is traditionally taught that when running an executable (a file with execute permission), the shell will fork() itself and have the child process replace itself using execve().
One winter a few years back, I random question popped in my head: Who determines whether a file is a script or an executable and where in the code does this logic lie in?
Recall to invoke a script or any non-ELF executables such as Python and Bash script, one needs to specify the path to the interpreter using the shebang directive (#!) such as
#!/usr/bin/bash
or
#!/usr/bin/python
I was unsure whether the responsability of executing the script properly was the job of the terminal (bash, sh, csh, etc) or the kernel. I highly suspected it was the role of the
kernel and randomly I came across an article How does Linux start a process that answers this question. In short, when one calls execve,
From there into
search_binary_handler()where the Kernel checks if the binary is ELF, a shebang (#!) or any other type registered via the binfmt-misc module.Excerpt from How does Linux start a process
/*
* cycle the list of binary formats handler, until one recognizes the image
*/
static int search_binary_handler(struct linux_binprm *bprm)
{
// ...
list_for_each_entry(fmt, &formats, lh) { //iterate through all registered binary format handlers
if (!try_module_get(fmt->module))
continue;
retval = fmt->load_binary(bprm); // attempt to load executable as the current format
// ...
if (bprm->point_of_no_return || (retval != -ENOEXEC)) { //format recognized so stop searching
read_unlock(&binfmt_lock);
return retval;
}
The kernel will call search_binary_handler() to determine the type the binary (executable) by iterating through all registered formats
which includes (not in order):
- ELF -
binfmt_elf - Scripts (
#!) -binfmt_script - Misc -
binfmt_misc: Linux (kernel) allows one to register a custom format by providing a magic number or a filename extension (see Kernel Support for miscellaneous Binary Formats)
Each binary format fmt (struct linux_binfmt has a function pointer load_binary used to load the binary. This is the function the
kernel uses to help identify the binary type as this function will return -ENOEXEC if the binary is not of its type.
/*
* This structure defines the functions that are used to load the binary formats that
* linux accepts.
*/
struct linux_binfmt {
struct list_head lh;
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
};
For scripts, the loader can be found in fs/binfmt_script.c a function load_script:
static int load_script(struct linux_binprm *bprm)
{
const char *i_name, *i_sep, *i_arg, *i_end, *buf_end;
struct file *file;
int retval;
/* Not ours to exec if we don't start with "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;
/*
* This section handles parsing the #! line into separate
* interpreter path and argument strings. We must be careful
* because bprm->buf is not yet guaranteed to be NUL-terminated
* (though the buffer will have trailing NUL padding when the
* file size was smaller than the buffer size).
*
* .... truncated ....
*/
// parsing logic
bprm->interpreter = file;
return 0;
Things to Look At Next
- Wonder about how Linux handles ELF binaries, specifically how it handles static and shared binaries? Take a look at How does Linux start a process
- fork() can fail: this is important
- TODO: Investigate why a script without shebang fails on
strace ./test- use
bpftrace:sudo bpftrace -e 'kprobe:load_script { printf("load_script called by %s\n", comm); }' - find other trace events to look at to distinguish between the two cases like exec
- use
- Edit (Nov 10): Someone posted today on Hacker News Today I Learned: Binfmt_misc which goes over
binfmt_miscfrom a security perspective- Links to ON BINFMT_MISC, a tutorial on how to register a new binary format
Hangul - Unicode Visualiser
October 31, 2025
Inspired by the best video I have encountered on Unicode, I was inspired to create a visualiser of how unicode represents Hangul, the Korean writing system, that was covered in the video.

Link to visualiser: https://zakuarbor.codeberg.page/unicode/hangul/
It is fascinating how one can represent all 11,172 possible combination so elegantly. The visualiser allows one to determine the codepoint of any Korean syllabic blocks. For those unfamiliar with the language, Korean is made up of 19 consonants (자음) and 21 vowels (모음) though some sources may say there are 24 basic letters (Jamo). The number does differ depending on how you count the letters but we can agree that there the language has 51 Jamo (there are 24 basic letters and from these you could form more complex consonants and vowels). To form a complete a syllable block (a word is made up of one or more of these blocks), there must be at least one consonant and one vowel that is attached to each other. A syllable block is made up of 3 components:
- An Initial constonant: 19 possible consonants
- Medial vowel: 21 possible vowels
- Final consontants (optional): 27 potential consonants to choose from including consonant clusters if one chooses to include one (though for the formula to work out, we have 28 options, option 0 being a “filler” (i.e. nothing)
Wikipedia has a great entry on how the letters are placed within a block. The purpose of the analyser is to visualise how Unicode computes the correct codepoint. There is actually no need to understand how the language works to understand how unicode is able to compute the codepoint associated with the block.
Random but here’s a great UTF-8 playground I encountered. I probably should update my visualiser/playground to include UTF-8 encoded representation.
UTF-8 Explained Simply - The Best Video on UTF-8
October 6, 2025
Video: UTF-8, Explained Simply
Channel: @nicbarkeragain (Nic Barker)
This is the best explanation I have found on UTF-8 thus far. I previously said UTF-8 is Brilliant was the cleanest explanation I’ve seen on this subject, well that was shortly beaten on October 2 2025. There are a few reasons why I love this video:
- Builds up the need for unicode via history and how the 8th bit on ASCII could be used as parity bit
- Interoperability
- How Unicode-8 is backward compatible - old ASCII format works with new decoder
- a brief history of how UTF-16 came to existence
- How Unicode-8 is also forward-compatible - UTF-8 remains compatible with existing ASCII decoder
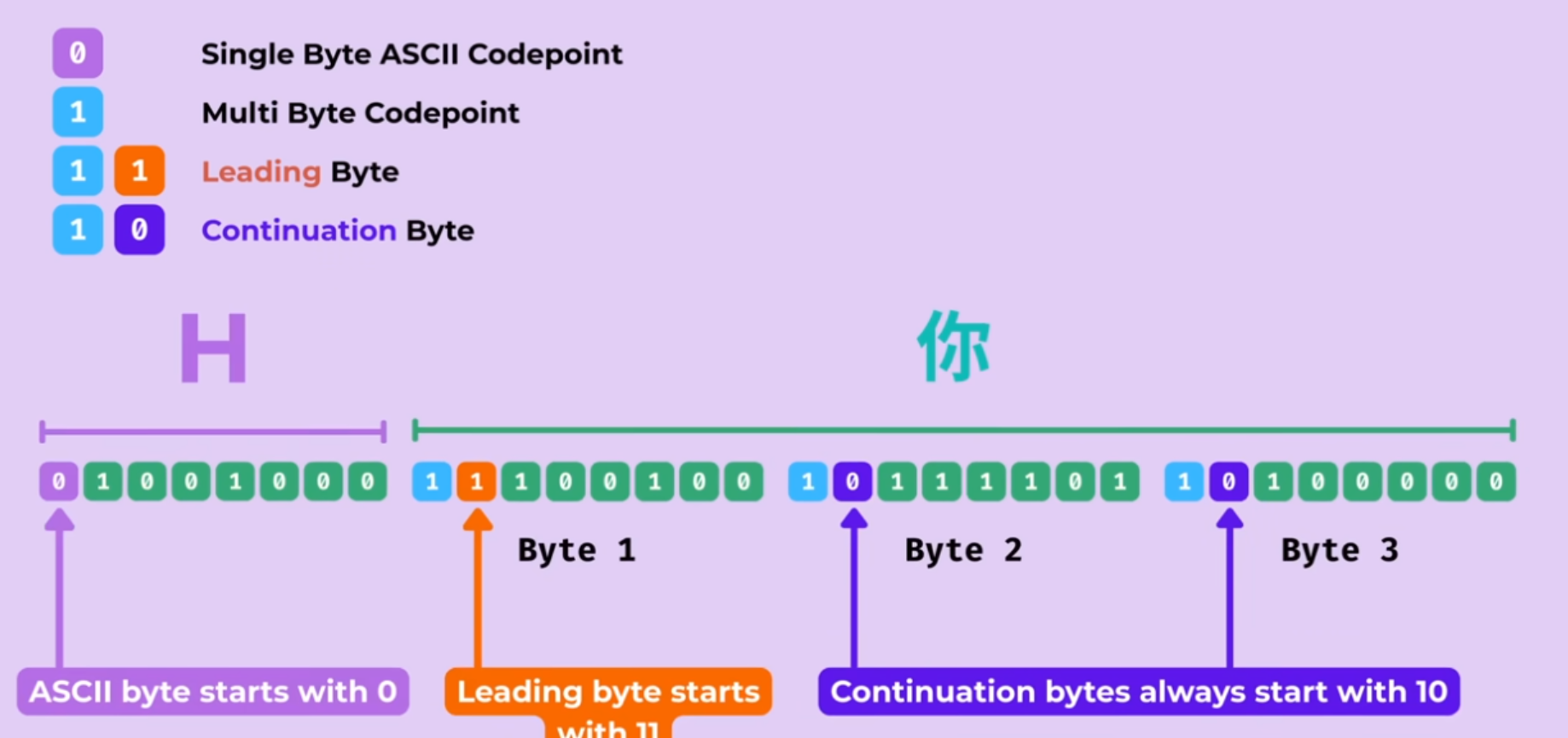
- Self-synchronization problem in Variable-width encoding bytecode - In the event of a data corruption, how do we know whether we are on the beginning or somewhere in the middle of a byte
- a question of how to identify the leading byte if dropped in a random chunk of data
- How to determine the first byte of a 2, 3, 4-byte code unit sequence
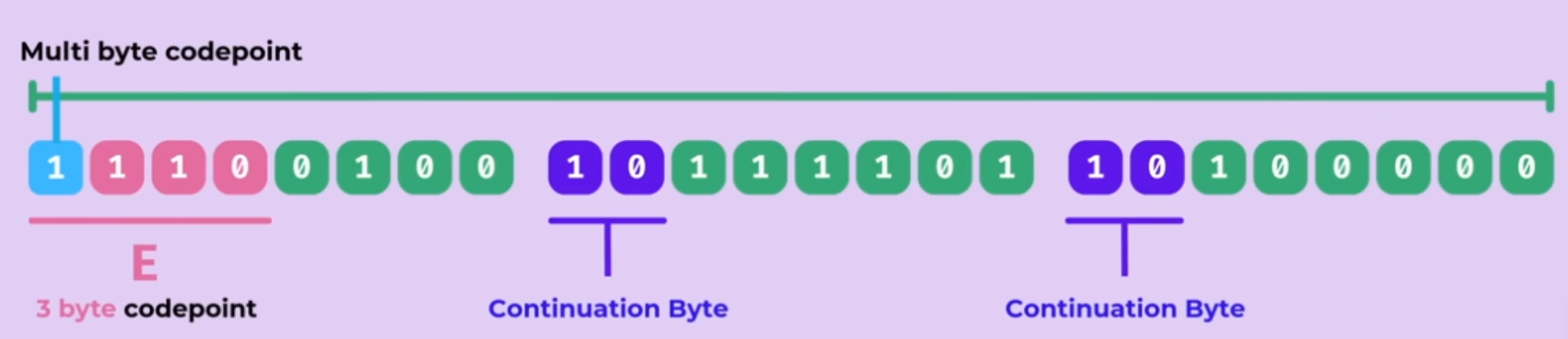
- How to avoid potential conflicts of codepoints existing in different byte sequence (only the shortest representation of a codepoint is used)
- Zero-width joiner to combine emojis
- How UTF-8 represents Korean - How UTF-8 allows you to construct and edit each block efficiently through Math

I definitely should edit my blog on character encoding as there are probably some areas that are quite questionable after going through various articles and videos on unicode over the year.
Render Archaic Hirigana
October 6, 2025
What does does U+1B002 look like on your screen? 𛀂
Did it look like some some unicode box inscribing the unicode value? That is because your system lacks the typefont to render the unicode.
If you visit the following wikipedia page on 変体仮名, you’ll likely notice the following:
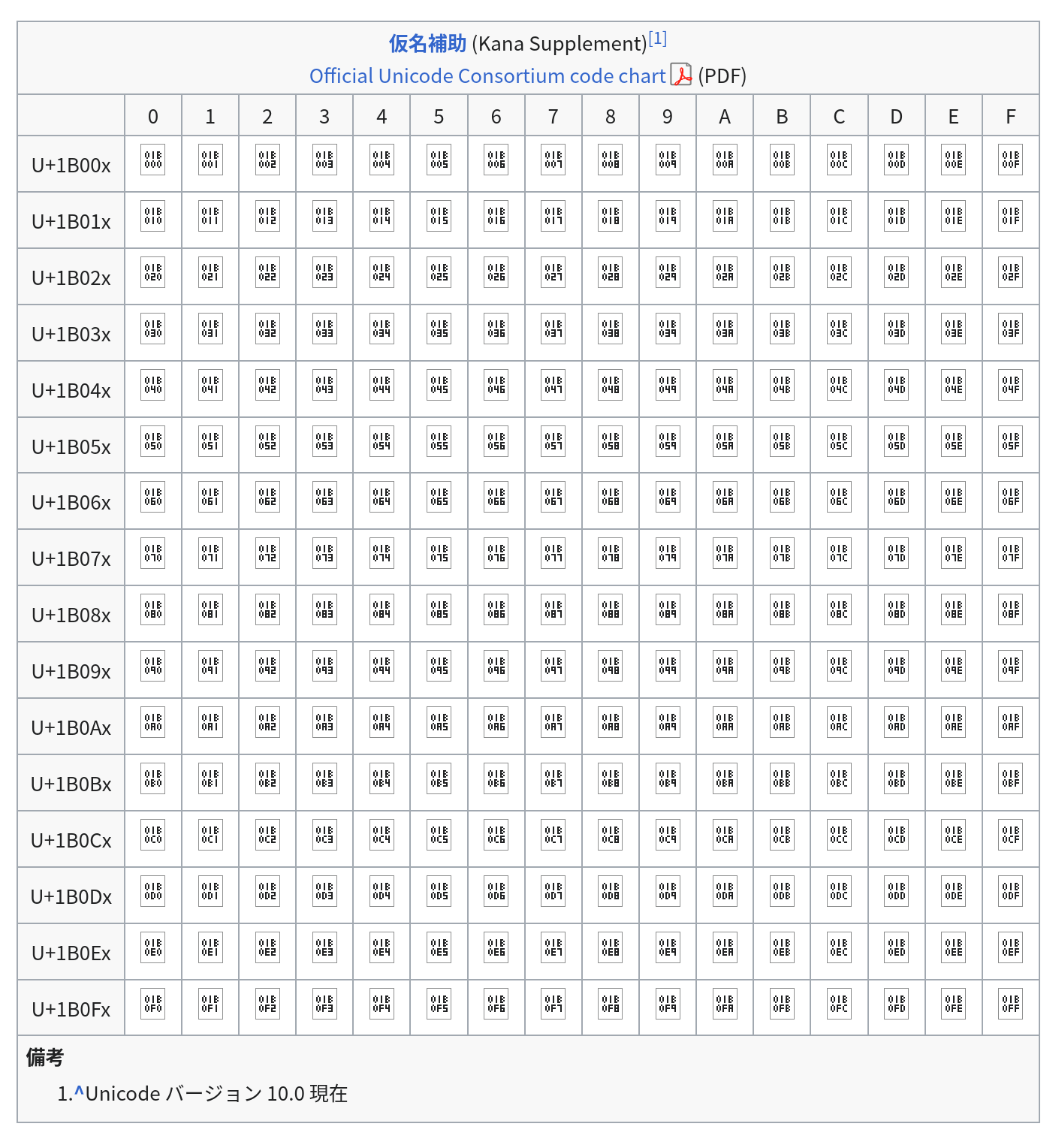
Instead of:
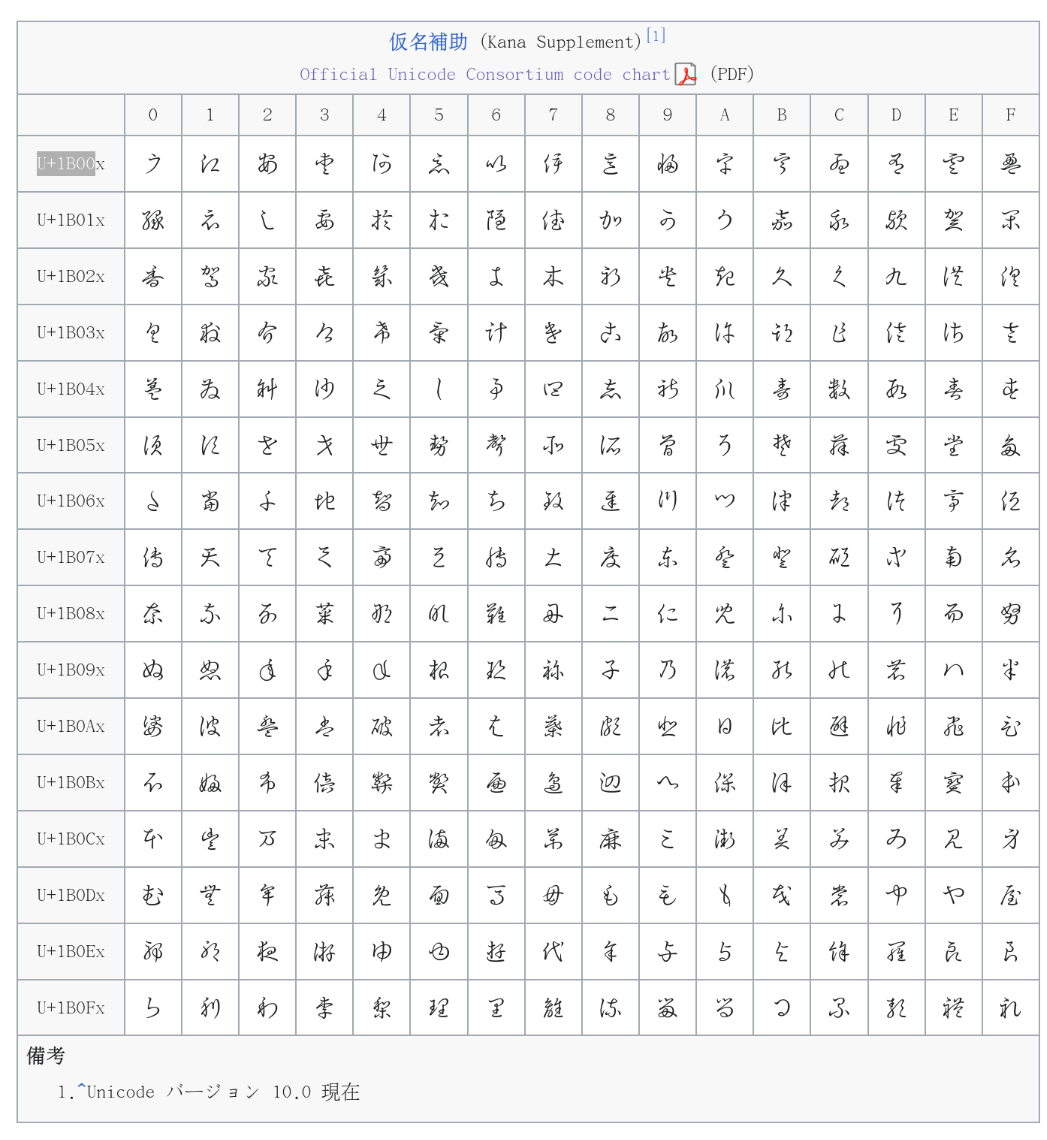
To resolve this, essentially install the true type font *.ttf file from BabelStone
Credits to the following article as it outlines much clearly how to install the font:
A Beginner’s Guide to Inputting Historical Kana: Installing a Font for “Hentaigana”.
I instead went through the harder route before reading this article by installing the font under ~/.local/share/fonts and running fc-cache -fv to forcibly reload the font.
Turns out you can install the GUI similarly to what the article proposes for MacOS by opening the file on Linux (double-tap) and an option to install the font will appear:
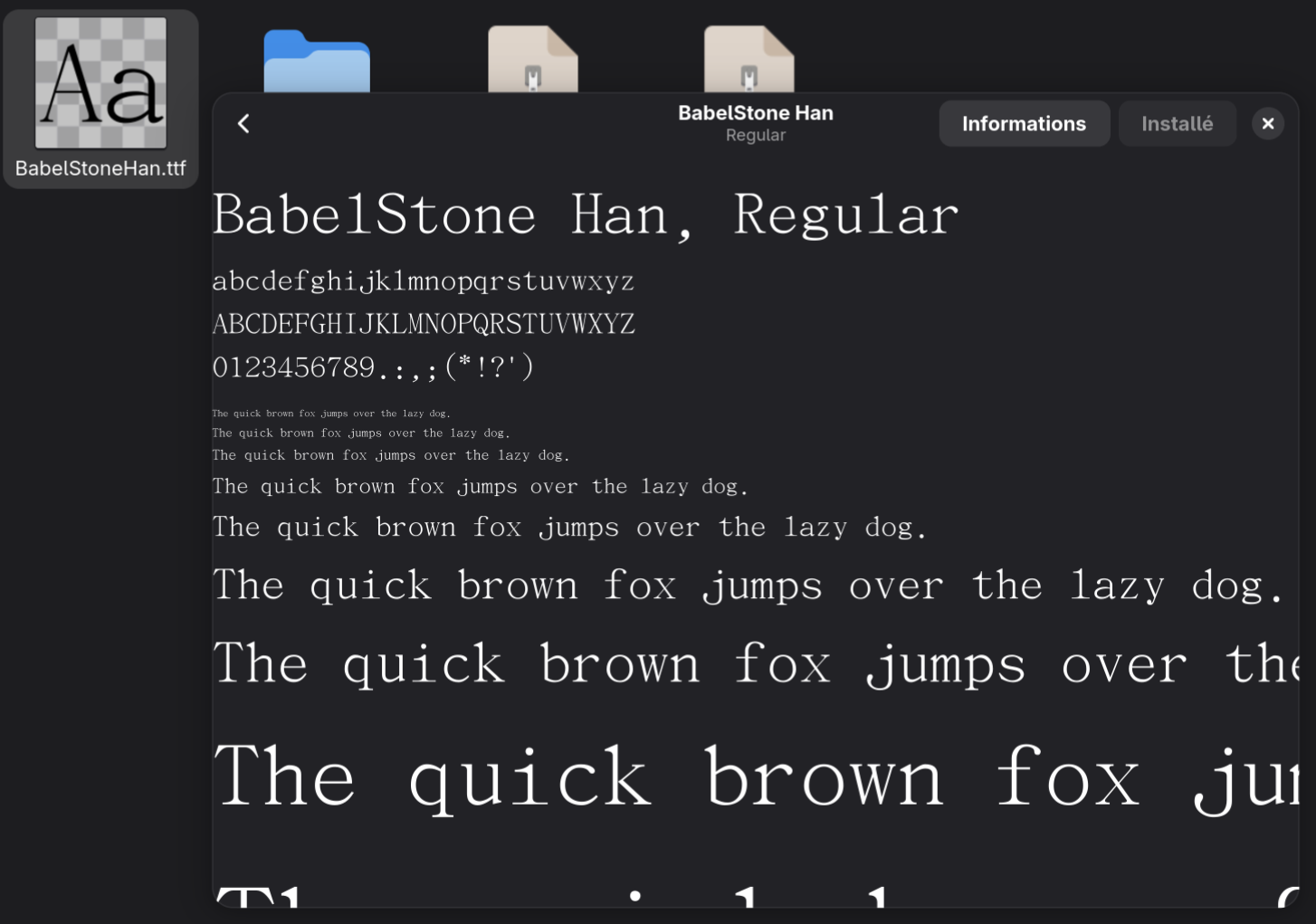
Refresh the page and you should now see 𛀂

Note: For some reason Firefox on Private-Mode is unable to render the archaic Hirigana, not sure why
Migrating Away Github: One Small Step To Migrate Away From US BigTech
October 3, 2025
As title suggests, I no longer actively use Github as my personal Git hosting service. This does not mean I have abandoned Github entirely as I still visit the site and use it regularly for work.
For a while, the code for this site, my blog, and my personal side projects have been hosted on Codeberg, a non-profit German organization that hosts their servers in Europe. Similar to my migration from Wordpress to Github, none of my content have been deleted but rather has been archived for data preservation and to prevent link rot. I originally discovered and created my Codeberg account when trying to replicate performance claim made by some in the Linux French forums.
This move does not imply any hatred or dislike of Github as a platform as it has served me well over the year. Rather, it reflects my gradual and slow effort to reduce reliance on Big Tech, especially those operated by large US companies. As the 2nd part of the title suggests, I have been wanting to DeGoogle and big tech in general for years. However, it has been hard to justify the move as I honestly don’t have too much qualms providing data to these giants. This seems very contradictory to others as I have made this argument a lot to push others to use Linux or any other open source POSIX-compliant OS (e.g. BSD). Though you should seriously consider leaving Windows if you have not have done so, it’s a bloated privacy-invading OS. I believe in the Right to privacy which Big Tech does not provide at all.
Due to the recent statements and actions coming from the United States, I have made the decision to start the migration to gain more independence from US tech and start searching for more open alternatives. I am still a slave to Google, relying on their entire ecosystem such as Google Playstore, Google Search, Google Drive, Gmail, Maps, Google Auth, Sign In via Google and Youtube. To minimize disruption and pain, I will be making a slow transition starting with replacing services and software that are the easiest to replace which happened to be Github. Currently, I am slowly transitioning my email to ProtonMail, migrating the most essential services first such as Banking. I do plan to keep my original email to remain in contact with anyone from the past and to tie any my insecure or data-invading services to Gmail, effectively creating a two-tier email system.
I do believe it is important to remain pragmatic when moving away from US tech. It is not realisitic to completely cutt off entirely from US tech given their dominant position in the market. After all, I earn my living from US companies who frankly create awesome products and do a lot of R&D that benefits society as a whole.
In other words, it is important to have a balance and identify which services can be replaced the easiest and which pose the greatest risk if access were suddenly restricted for injust reason. As part of the effort, I have made an offline backup of my data on Google Drive (though whether the archives contain any corruption, time will tell).
I still have not identified the next platform to replace but here are some ideas:
Authenticator - I need cloud sync. Losing my phone on the bus nearly locked me out of all my accounts which cloud backup to my tablet saved me- I carry a Yubikey around with me but not every service supports this yet
- Edit (Nov 9): - I have made the full transition to ProtonAuth
- Office Suite - A cloud office suite such as Google Drive are hard to give up due to its ease of sharing and collaboration tools. The most realistic path is to self-host.
- ProtonDrive nor does La Suite, French Government Suite, have replacement for Presentation and Spreadsheet at the time of writing
- Collabora and OnlyOffice seems to be the only alternatives
- Phone - I currently use a Google Pixel 6a which has served me well till the summer when Google released an update that reduces battery capacity
I am hesitant to move to GrapheneOS since I am not sure if it supports my workplace’s authentication apps- Updates(Nov 9): I no longer use my personal phone to authenticate workplace applications, security didn’t like the fact I was using a third-party VPN and that I didn’t install workplace monitoring services (now using Okta Desktop to authenticate to avoid installing spyware on my phone)
Fairphone 6 would be ideal but is not available in my region so for now Samsung appears to be the only practical alternative though I don’t plan to replace my phone until reaches end-of-life as I have always done with my previous phones- Edit (Nov 9): Apparently Fairphone 6 is region-locked and will not work in North America
- Cloud Provider - At the moment, I don’t maintain any cloud instances since I no longer have a need for it (I previously used DigitalOcean and free-tier Oracle cloud).
I no longer have any cloud instances with any provider currently as I no longer have any use for them (I used Digital Oceans previously)
- OVHCloud - French cloud service whom I found out about via an article from the Register where Microsoft could not guarantee data sovereignty. However it does not seem they have any ROCm enabled GPUs which may pose an issue if I wanted to do any ROCm related work in the future (though I guess it would make more sense to use CUDA or write HIP programs)
- Search Engine: Google has been great to me thus far. I know others complained its search results have gotten worse over the years but it has been far better than other search engines I have used in the past such as Yahoo, DuckDuckGo, Brave Search and Ecosia. I heard Kagi is a good alternative, I should try the free version and see for myself before I make any commitment.
Binary Dump via GDB
October 2, 2025
Recently at work, I’ve been relying on a very handy tool on GDB called dump memory to dump the contents of any contiguous range of memory.
I first came aware of this tool from a stackoverflow answer
that a coworker linked as each of us had a need to dump the contents of memory copied from the GPU to the host memory for our respective tickets.
Syntax: dump memory <filename> <starting address> <ending address>
For instance,
dump memory vectorData.bin 0x7ffff2d96010 0x7ffff53bba10
or suppose you have a vector vec, you could dump the contents of the vector via:
dump memory vectorData.bin vec.data() vec.data()+vec.size()
Gundam With Decent Portrayal of Code
August 27, 2025
Years ago I encountered a Reddit post asking us redditors to rate a piece of code shown in Mobile Suit Gundam 0083: Stardust Memory. This led to an interesting discussion and analysis of the code from a few redditors, particularly the analysis from gralamin who disected the code revealing a few interesting aspects of the code such as the potential architecture, OS, and purpose of the code.

Based on the release date of the anime along with the provided code, we can infer the following:
- Code is written for x86-16-bit DOS based on
- the use of far pointers
- reference to the DOS Command-line interpreter COMMAND.COM, the precursor of cmd.exe
- There is some IPC (Inter-process communication) going on whereby there is a parent process (named mother) and a child process
- NOTE: COMMAND.COM runs programs in DOS
- DOS system was set for Japanese locale using JIS X 0201 as their characterset
When I initially saw the post 3 years ago, I initially thought broken¥n was a typo seeing how there was a few spelling mistake in the document such as equall and memeory. However,
as gralamin alluded:
I’m not sure what is up with the yen n. Maybe at the time \ was mapped to yen on japanese machines, in which case this would be a new line.
After spending hours reading up on character encoding due to a request from a friend studying Linguistics, I now can confirm his speculation was indeed correct.
From the ASCII table, we can see that 0x5C maps to backslash \n
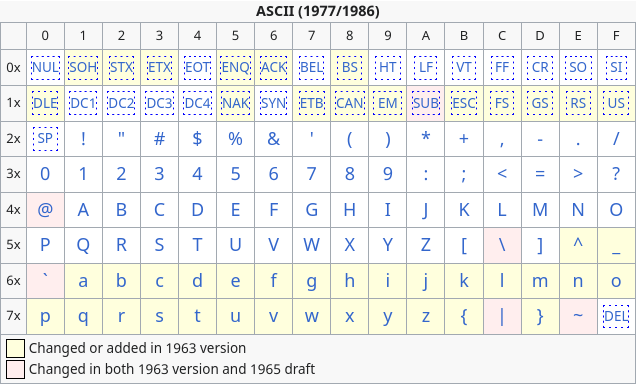
ASCII Table. Extracted from Wikipedia
JIS X 0201 can be seen as an extension of ASCII where the upper unused bits were repurposed to contain Katakana characters and a few other things. However there are some slight differences as highlighted in yellow:
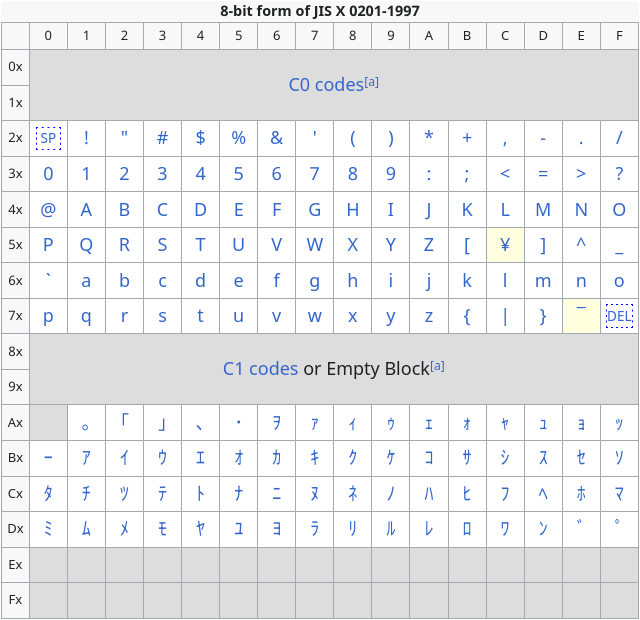
JIS X 0201 Table. Extracted from Wikipedia
As one can notice 0x5C no longer maps to baskslash \n anymore but rather to the Japanese Yen ¥. This makes no difference to the compiler’s perspective as from its perspective
as \ and ¥ has the same value. Wikipedia has a good comment about this effect:
The substitution of the yen symbol for backslash can make paths on DOS and Windows-based computers with Japanese support display strangely, like “C:¥Program Files¥”, for example.[14] Another similar problem is C programming language’s control characters of string literals, like printf(“Hello, world.¥n”);.
Whether intentional or not by the artist, this rendering shows some realism in the show (let’s ignore the fact the female lead is not Japanese).
Incorrect Translation of a Math Problem in a Manga
July 24, 2025
Recently I have been slowly reading through Danchigai, a comedy and slice of life manga in French. Whenever there is a math or code displayed in anime or manga, I sometimes have the temptation to analyze the problem. In chapter 27, the following problem was presented:

It is immediately obvious that there is a mistake during the fan-made scanlation of the manga from Japanese to French. In the original question, $(x^2-3x)+5x(x^2-4x)+4$, the highest order (degree) is 3 but the reported answer has the order of 4.
So I decided to take a look at the fan-made English scanlation and notice that the scanlator left the question in its original form:

With the original question unmodified from the Japanese source, we can now verify the answer:
\[\begin{align*} (x^2-3x)^2 + 5(x^2-3x) + 4 &= u^2 + 5u + 4 \quad \text{, } u = x^2-3x \\ &= (u+1)(u+4) \\ &= (x^2-3x+1)(x^2-3x+4) \quad \text{ as desired} \end{align*}\]Rational Inequality - Consider if x is negative
July 23, 2025
Someone posted on a group chat a snippet from his course notes:
i.e., it is WRONG if you try to do: $\frac{1}{x} \ge 2 \iff 1 \ge 2x$
and it was not clear to them as to why that is.
This seems like an innocent attempt to solve the inequality and it is not entirely incorrect to do so. But when working with rational inequality, one needs to consider the signedness of x (i.e. is x negative or positive). The inequality could change depending on whether x is positive or negative.
To give a clearer picture, take a look at the graph of $\frac{1}{x}$ and notice how the function behaves differently when x is before or after the vertical asymptote.
Here’s my crack at the problem, hopefully I didn’t mess up:
if $x> 0:$
\[\begin{align*} \frac{1}{x} &\ge 2 \\ \iff 1 &\ge 2x \\ \iff x &\le \frac{1}{2} \end{align*}\]if x = 0: Not possible (DNE)
if $x < 0$:
\[\begin{align*} \frac{1}{x} &\ge 2 \\ \implies \frac{1}{(-x')} &\ge 2, \quad x' > 0 \text{ & } x=-x' \\ \implies -1 &\ge 2x' \\ \implies \frac{-1}{2} &\ge x' \end{align*}\]Recall $x’> 0$, but we found $x’\le \frac{-1}{2} < 0$ . This is a contradiction and therefore $x’ \not \lt 0$
We have the following:
-
$x \lt \frac{1}{2}$
-
$x\ne 0$
-
$x \not \lt 0$
$\therefore x \in (0, \frac{1}{2}]$
The Issue With Default in Switch Statements with Enums
July 4, 2025
Reading the coding standards at a company I recently joined revealed to me the issue with default label within the switch statement and why it’s prohibitted when its being
used to enumerate through an enum. default label is convenient to handle any edge cases and it’s often used to handle errors. However, when working with enums, it is often
the case that the prpogrammer intends to handle all possible values in the enum and would turn on -Wswitch or -Werror=switch.
Let’s suppose I have an enum to represent the different suite in a deck of cards:
enum Suit {
Diamonds,
Hearts,
Clubs,
Spades
};
and my break statement looks like the following:
switch(suit) {
case Diamonds:
printf("Diamonds\n");
break;
case Hearts:
printf("Hearts\n");
break;
case Clubs:
printf("Clubs\n");
break;
}
}
The code above is missing the Spades suite so if we were to compile with -Wswitch:
$ LC_MESSAGES=C gcc -Wswitch /tmp/test.c
/tmp/test.c: In function ‘main’:
/tmp/test.c:12:3: warning: enumeration value ‘Spades’ not handled in switch [-Wswitch]
12 | switch(suit) {
| ^~~~~~
Note: LC_MESSAGES=C is just to instruct GCC to default to traditional C English language behavior since my system is in French
But if we were to add the default case:
switch(suit) {
case Diamonds:
printf("Diamonds\n");
break;
case Hearts:
printf("Hearts\n");
break;
case Clubs:
printf("Clubs\n");
break;
default:
}
Then we will no longer see the error
$ LC_MESSAGES=C gcc -Wswitch /tmp/test.c
$
However, we can get around this issue by being more specific with our warning flag using -Wswitch-enum:
$ LC_MESSAGES=C gcc -Wswitch-enum /tmp/test.c
/tmp/test.c: In function ‘main’:
/tmp/test.c:12:3: warning: enumeration value ‘Spades’ not handled in switch [-Wswitch-enum]
12 | switch(suit) {
| ^~~~~~
Note that -Wall won’t catch this error:
$ LC_MESSAGES=C gcc -Wall /tmp/test.c
$
2025 Update
May 24, 2025
Website
Since the last last update when I decided to revive my neocities website, there has been a lot more activities. Unfortunately, due to low motivation and laziness, I have not been able to finish a number of blogs and microblogs … There are definitely a number of topics I want to explore but I am in a slump and need to make some changes in how I manage my time … to be more productive. I’ve been reading less blogs and articles so the LinkBlog is starting to look bare …

Academic Studies
Previously I mention that I lost a lot of my initial interest in the domain after the 3rd year of my studies and therefore decided to take a year-long break from my studies to pursue an internship in telecom. The experience was … boring … I loved having lunches and taking walks with the team but the work was dull.

Originally I was supposed to find a summer job before returning to school in the fall but due to my impatience, I ended up signing a 16 months contract with an enterprise who designs CPUs and GPUs … so I am placing my education on hold for another year …

To give more context, most of the summer jobs are posted in the winter. However, I started my job search in the fall where most of the long term interships are available. After being rejected from what I thought would be a decent chance to get into the government for the summer (I’ve interviewed with them in the past and did very well but this time, they rejected me on the first stage of the interview), I ended up applying to any jobs that sounded remotely interesting regardless of their lengths of work. That is how I ended up moving around 400km away from my hometown and also delaying my graduation. It is getting scary because it’s been so long since I’ve done any serious Mathematics. To those who studied Engineering, the Math you do is vastly different from the Math I take, I know this as a student who had to start from year 1 despite having completed a degree in Computer Science which is way closer to Math than Engineering is to Math. It does depend on your country and institution, but there is a huge difference between the Math for future Mathematicians-wannabes and everyone else. It is a bit weird to explain but in Canada, the Math major is split into two categories:
- Math for those wishing to go to graduate school in Mathematics or do serious Math
- Math for those who wish to study Mathematics but not necessary pursue higher education in the field
In the former, students are exposed to some concepts of real analysis in their first year and is very theoretical and proof heavy. There’s little computation in the program. In the latter, students are exposed to proofs from a course on Mathematical proofs but it is identical to what Computer Science students had to take at my alma mater. The program is more computational heavy and resembles the Math courses that CS and Engineers take but with a bit more emphasis on theory.
Meeting my friends before my move and seeing them graduate and starting graduate school made me miss Math a bit. Although I did lose a lot of my initial interest in the subject, I do still want to look into the subject a bit more. Perhaps I’ll review some stuff from linear algebra (you should definitely read Linear Algebra Done Right if you are interested in the theory aspect), read some entertaining Math books (i.e. Math Girls series), and look into Mathematics for Machine Learning or Robotics during my spare time.
What I’m Doing Right Now
As I mentioned, I’ll be working for another year at a company in their GPU division. I’m not doing anything exciting but it’s definitely way more exciting than my previous internship. I’ve been having fun reading their new test and verification framework and learning the internals of their GPUs including the hardware architecture and assembly, something I’m not too familiar with and outside of my expertise. Though, I only need to know at a high level of the various components of the GPUs and writing basic shaders in assembly for my role.
It has been exactly a year since I’ve seriously started to study French and I sure did overestimate my knowledge of the French grammar … While I learned a lot, my progress in the language has not been smooth. Considering languages is my weakest subject, my progress has been acceptable. For context, despite only speaking English fluently, I struggled to learn a single language which greatly impacted my academic performance. I actually have been provided a translator before when I was a kid, and I’ve been asked if I was international due to my poor English in Highschool.
The French language can be broken down into 3 categories or 6 levels if we follow CEFR (Common European Framework of Reference). I stupidly chickened out of A2 (advanced beginner) back in November so I asked the examinators if I could downgrade my level to absolute beginner. Unsurprisingly, I aced it as it. In March, I took the advanced beginner exam (A2) and also aced it which was also not a surprise considering I was originally planning to take the exam back in November.

I plan to continue my studies in French for the next year and take the “lower intermediate” (B1) exam in the coming Fall. Lately, I’ve been debating if I should pick another language such as my mother tongue now that my parents will never know that I am learning it (I would hate if my parents find out because they would be so happy but it would make communication easier as we can stop goolging words and also stop relying on translations to communicate with each other. I am not too close to my parents so I never picked up the language). Though I don’t know how feasible it is to learn 2 languages, learn CS, and Math would be … very difficult to juggle.

Learning my mother tongue has always been in my list of to do but something I’ve put off since it wasn’t a priority. It sure would be less awkward when strangers communicate with me in Korean or request that I do translation for either a visiting or new Engineer from Asia since everyone assumes I’m not a native English speaker due to my mediocore English profeciency and name. Though if I was to pick up my mother tongue, it would only be till the latest available language exam available in the near available city before I return to school. Then I’ll place my studies on hold till after I become fluent in French. Though I do wonder where this thought to learn another language came from. Perhaps it’s my manager saying random Korean greetings to me (which I ignore because I’m not sure what to respond without revealing my equally terrible prononciation).
I want to conclude that Youtube Shorts are evil and Youtube should give users the option to disable this feature. Short form is ironically a big time consumer despite its length. It is just way too addicting.

DuoLingo Dynamic Icons on Android
May 6, 2025
Recently, I have been noticing that the icons for Duolingo changes throughout the day depending whether if I have done my daily exercise:

Originally I thought this feature is called adaptive icons due to its name but it is not.
In Android Development, there is a file that contains information about your app such as the permissions, minimum device versions, name of the app and etc in the AndroidManifest.xml.
This file also includes the icon to use for the app if provided. Apparently there is something called activity-alias
provides more flexibility and allows you to enter the same activity (i.e. think of it as a page or a view in the app). Essentially you can enable or disable different aliases to swap the icons via PackageManager.ComponentEnabledSetting and this is likely the approach that Duolingo
uses. They probably run some background process that is hopefully scheduled at certain periods of time such as WorkerManager.
I am not too familiar with Android development so most of this is just speculation. It’s been many years since I last wrote an Android Application and it was quite primitive … I hated Android Studio … it killed my poor underperforming laptop
Behavior of Square Roots When x is between 0 and 1
April 14, 2025
Small numbers between 0-1 has always stumped me as it’s behaviors seemed unintuitive. For instance:
- $0.5^2 = 0.5 \cdot 0.5 = 0.25$
- $\sqrt{0.5} \approx 0.707106781$
which implies for $x \in (0,1)$:
- $x^2 \lt x$
- $\sqrt{x} \gt x$
I can rationalize in my head the first example by transforming the problem $x^2$ from an abstract equation into a more concrete word problem:
What is half of a half
Half is 50% and a half of 50% is 25%. While suffice enough to convince my brain, this lacks sufficient rigor in Mathematics. So let’s go through the proof a bit more formally as to why $x^2 \lt x$ because we’ll need this premise to explain why $x \lt \sqrt{x}$ for $x\in \{0,1\}$:
\[\begin{align*} 0 &\lt x \lt 1 \\ x\cdot 0 &\lt x\cdot x \lt 1\cdot x \\ 0 &\lt x^2 \lt x \end{align*}\]There are two ways I can think when it comes to explaining why $x \lt \sqrt{x}$:
1. Graphically:
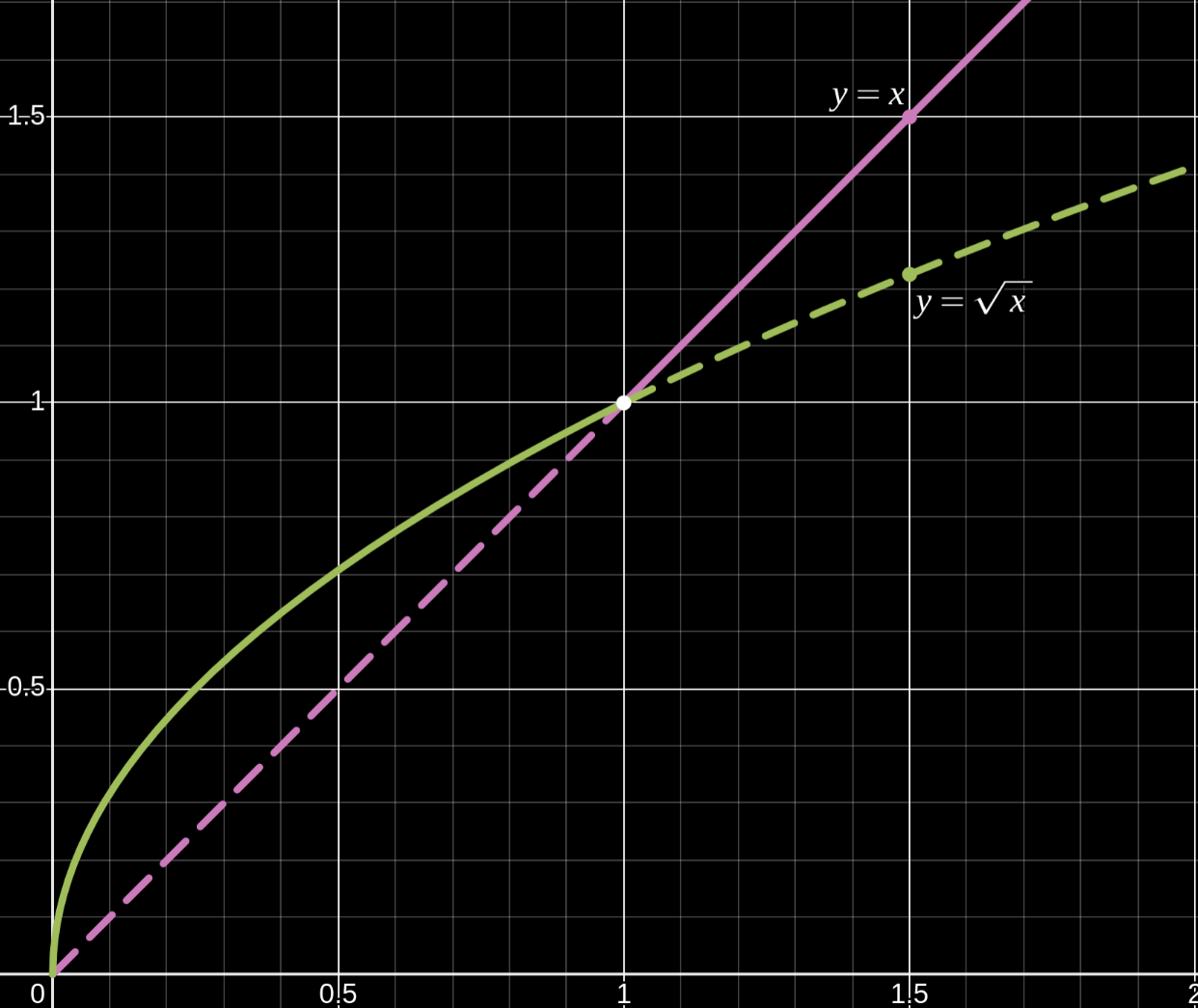
Observe how the root function $\sqrt{x}$ domaintes the linear function $x$ for $x\in (0, 1)$ i.e. $x \lt \sqrt{x}, \forall x \in (0,1)$
2. Formal Proofs:
\[\begin{align*} 0 &\lt x \lt 1 \\ 0\cdot x &\lt x \cdot x \lt 1 \cdot x \\ 0 &\lt x^2 \lt x \\ \sqrt{0} &\lt \sqrt{x^2} \lt \sqrt{x} \\ 0 &\lt |x| \lt \sqrt{x} \quad x \gt 0 \\ 0 &\lt x \lt \sqrt{x} \\ & \boxed{x \lt \sqrt{x} \quad \forall x \in (0,1)} \end{align*}\]or given $x^2 \lt x \quad \forall x \in (0,1)$ as shown in the beginning:
\[\begin{align*} x^2 &\lt x \\ \sqrt{x^2} &\lt \sqrt{x} \\ |x| &\lt \sqrt{x} \\ &\boxed{x \lt \sqrt{x} \quad \forall x \in (0,1)} \end{align*}\]4 is less than 0 apparently according to US Trade Representative
April 8, 2025
Note: After publishing the post, turns out $\epsilon < 0$ could be correct, but $\epsilon$ should have been -4 instead.
A friend shared with me the recent and infamous Math equation that has trade and economic experts scratching their head:
\[\Delta \tau_i = \frac{x_i - m_i}{\epsilon \varphi m_i}\]I am not going to discuss about poltics nor my opinions about the use of this equation. Nor will I discuss about the equation itslef, there’s plenty of journalists, economists, and mathematicians who could comment more on this. I will instead be talking about a contradiction that appears in their website taken on April 7 2025:

This is a typo because what they probably wanted to say is that $\epsilon > 0$ because they either introduced a contradiction or stating that $4 < 0$ during their calculations:

If $\epsilon < 0$ and $\epsilon = 4$ then that would imply that $\epsilon = 4 < 0$ which is a contradiction. It would be mean of me to pick on the administration for this apparent contradiction since typos do happen, even to professionals. Though the story would be different if this contradiction with $\epsilon$ impacted the lives of others. I’m not saying this formula does not have large impact on others, I’m trying to say that their typo stating $\epsilon < 0$ is unlikely to cause chaos. What does not make sense to me is how no one in the Trade Representive office bothered to correct this contradiction yet.
Row Major v.s Column Major: A look into Spatial Locality, TLB and Cache Misses
March 16, 2025
Memory is often the bottleneck of programs. When writing programs, it is important to consider how data is structured based on their data accesses patterns. A classic example is accessing a matrix via row or column major i.e. going through a matrix by row or by column order.
Theory: Accessing a matrix by row-major will benefit from spatial locality as the next few elements will be accessed in the subsequent iterations and thus benefit from cacheline populating the next few elements on each cache miss. As column-major accesses elements that are spread apart, it will not benefit from the cache as much as the stride is sufficiently large enough that the CPU is less likely to retrieve the next subsequent elements within the column. Therefore, column-major accesses will suffer from higher cache and TLB misses so we should expect more cache accesses and page walks.
Theoretical/Expected Results:
| Events | Row-Major | Col-Major |
|---|---|---|
| Cache Accesses | Low | High |
| Cache Misses | Low | High |
| TLB Acceses | Low | High |
| TLB Misses | Low | High |
Results: Running perf stat -e dTLB-load,dTLB-load-misses,cache-misses,cache-references ./row_<major|col>:
| Events | Row-Major | Col-Major |
|---|---|---|
| Cache References | 164,724,829 | 1 559,702,701 |
| Cache Misses | 164,010 | 1,071,496,040 |
| dTLB Loads | 2,271,442 | 274,596,480 |
| TLB Misses | 2,232,796 | 273,704,958 |
As expected, we do observe column major suffering greatly from its inability to utilize spatial locality. We can observe large magnitudes of cache accesses and dTLB loads compared to row major whereby cache is missed 68.7% of the time. This there translates to more than double the runtime performance slowdown (almost 3 times on my machine):
hyperfine --warmup 1 -i --export-markdown runtime.md ./row_major ./column_major
Benchmark 1: ./row_major
Time (mean ± σ): 3.629 s ± 0.146 s [User: 2.597 s, System: 1.011 s]
Range (min … max): 3.519 s … 4.006 s 10 runs
Benchmark 2: ./column_major
Time (mean ± σ): 10.793 s ± 0.290 s [User: 9.716 s, System: 1.024 s]
Range (min … max): 10.412 s … 11.201 s 10 runs
Summary
./row_major ran
2.97 ± 0.14 times faster than ./column_major
The Bit Size of the Resulting Matrix
March 7, 2025
Recently I have started reading Performance Analysis and Tuning, and a passage made me ponder more time than I would like to admit:
Intel’s AMX extension, supported in server processors since 2023, multiplies 8-bit matrices of shape 16x64 and 64x16, accumulating into a 32-bit 16x16 matrix.
If you understand how matrix multiplication works, it is obvious as to why two non-square matrices results in a square matrix and also why 16x64 matrix must be multiplied by some matrix that has 64 rows. However, what my brain was stuck on was why the entries in the resulting matrix had to be 32-bit long and not 16 bits for instance.
It was only when I got my calculator that I understood why which shows my lack of experience working with bits since in Mathematics class, we never need to care about how many bits a number needs to be represented.
If we assume unsigned 8-bit integer, the highest number that can be represented is $2^8 - 1 = 255$ or $1111\ 1111_2$. Multiplying 255 by itself would obviously result in a larger number and therefore would require more than 8 bits to store the product. 255 * 255 = 65025 which can be represented in binary as:
\[1111\ 1111\ 0000\ 0001_2\]To represent the largest possible product between two 8-bit unsigned integer requires 16 bits. But due to how matrix multiplication works, each entry of the resulting matrix multiplication is the sum of 64 individual products. For an entry $c_{ij}$ in the resulting matrix:
\[c_{ij} = \sum_{k=1}^{64} a_{ik}b_{kj} \text{, for i,j = 1, ..., 16}\]If we were to add the largest possible product 64 times, then it would be 64 * 65025 = 4 161 600 which far exceeds the maximum range that an unsigned 16-bit integer can represent ($1111\ 1111\ 1111\ 1111_2 = 65\ 536$). Therefore each entry in the resulting matrix must be represented by at least 22 bits to taken into account of the largest possible entry from the product between the two 8-bit matrices. However, as we prefer to have sizes that naturally aligns with a power of 2, 32 bits would be the amount of bits required to store the product between 8-bit matrices of the shape 16x64 and 64x16.
Compiling and Running AARCH64 on x86-64 (amd64)
March 7, 2025
Cross-compilation targetting ARM architecture does not work out of the box in Fedora unlike what it would seem on Ubuntu based on what I am reading online. Nonetheless, the unofficial packages for arm gnu gcc toolchain works like a charm unlike the official toolchain. While I have not done my due diligence to figure out how to cross-compile on Fedora properly as I tried to cross-compile right before I sleep. My impatience and tiredness, I did not manage to get the official toolchain from the ARM website to work as it would complain about missing some libraries. I cannot recall if this was from the official ARM toolchain or from Fedora’s official package but I get issues like the following:
$ aarch64-linux-gnu-gcc test.c -o test -static
test.c:1:10: erreur fatale: stdio.h : Aucun fichier ou dossier de ce nom
1 | #include <stdio.h>
| ^~~~~~~~~
compilation terminée.
lantw44’s build of the AArch64 and the 32-bit ARMV7 GNU toolchain worked flawlessly.
Installing AArch64 Linux GNU Toolchain, one can now compile their C code for 64-bit ARMv8
with aarch64-linux-gnu-gcc:
$ aarch64-linux-gnu-gcc test.c -o test -static
$ file test
test: ELF 64-bit LSB executable, ARM aarch64, version 1 (GNU/Linux), statically linked, BuildID[sha1]=fc8921dfcad1a2a6aeeda3ebdff5d0c296dda865, for GNU/Linux 3.7.0, with debug_info, not stripped
To run the binary on your AMD64 Fedora Machine, you can simply use QEMU on user mode: qemu-aarch64-static for statis binaries
$ qemu-aarch64-static ./test
char is unsigned
If you compiled the binary as a dynamically linked binary, then you’ll need to use qemu-aarch64. However, this will require more work:
$ qemu-aarch64 ./test
qemu-aarch64: Could not open '/lib/ld-linux-aarch64.so.1': No such file or directory
$ qemu-aarch64 -L /usr/aarch64-linux-gnu/sys-root/ ./test
char is unsigned
You will need to provide the path of aarch64 system root: -L /usr/aarch64-linux-gnu/. If you don’t have sysroot, you probably can just install one of the following: dnf provides */ld-linux-aarch64.so.1
I probably could get the official ARM toolchain or official Fedora’s package to work if I fiddled with the compilation flags but I found lantw44 didn’t require
much work to get things to work out of the box.
top and Kernel Threads
February 23, 2025
Recently I was curious if I am able to trick top to believing a userspace thread is a kernel thread. For context, a kernel thread unlike its userspace counterpart
only exists within kernel space and lacks an address space. Another note is that kernel threads can only be created by other kernel threads such as forking the kthreadd process
(PID 2) via the clone() systemcall. Kernel threads can be spawned by struct task_struct *kthread_create().
There are lots of kernel threads running on your system such as ksoftirq or kworker threads as seen below:
$ ps -ef | grep -E "UID|\[" | head
UID PID PPID C STIME TTY TIME CMD
root 2 0 0 févr.20 ? 00:00:00 [kthreadd]
root 3 2 0 févr.20 ? 00:00:00 [pool_workqueue_release]
root 4 2 0 févr.20 ? 00:00:00 [kworker/R-rcu_gp]
root 5 2 0 févr.20 ? 00:00:00 [kworker/R-sync_wq]
root 6 2 0 févr.20 ? 00:00:00 [kworker/R-slub_flushwq]
root 7 2 0 févr.20 ? 00:00:00 [kworker/R-netns]
root 10 2 0 févr.20 ? 00:00:00 [kworker/0:0H-events_highpri]
root 13 2 0 févr.20 ? 00:00:00 [kworker/R-mm_percpu_wq]
root 14 2 0 févr.20 ? 00:00:00 [rcu_tasks_kthread]
Do you notice any pattern among kernel threads?
- kernel thread CMD name is enclosed in square brackets
[] - kernel threads have a parent id of 0 or 2
Based on the provided information, one would come to the conclusion that it is not possible. Based on one of the comments on Stack Overflow,
they seem to have suggested that ps and top distinguish whether a process is a kernel thread based on whether it has a cmdline (i.e. /proc/<pid>/cmdline).
For instance, let’s look at a kernel thread kworker/R-btrfs-worker, the cmdline file for this kernel thread should be empty as suggested above
$ ps -e | grep kworker | grep btrfs-worker
1339 ? 00:00:00 kworker/R-btrfs-worker
$ cat /proc/1339/cmdline | wc -l
0
If we were to look on Github, it would appear that the user appears to be correct.
/* if a process doesn't have a cmdline, we'll consider it a kernel thread
-- since displayed tasks are given special treatment, we must too */
Note: I want to stress the user did not say relying on an empty cmdline is a reliable way to determine if a process is a kernel thread.
However, this is for procps-3.2.9 which was released at least more than 15 years ago. A lot has changed since then and there are better ways to determine whether a thread is a kernel thread or not as listed by the various answers on stackoverflow.
I did not dig deep into the implementation of top to understand whether it really does rely on this cheap heurestic but if we were to look at htop, it takes advantage of checking
whether or not PF_KTHREAD bit flag is set:
if (lp->flags & PF_KTHREAD) {
proc->isKernelThread = true;
}
where in sched.h:
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
Taking a look at a more recent implementation of top suggests that this cheap heurestic won’t be effective of checking whether or not cmdline is set won’t work:
if (PT->hide_kernel && (p->ppid == 2 || p->tid == 2)) {
where kernel threads are now identified by checking whether or not the process is kthreadd (tid 2) or its children. To conclude, my original idea to trick top will not suffice.
this: the implicit parameter in OOP
February 11, 2025
I was recently reminded that the variable this is an implicit parameter passed to all methods in OOP such as C++. We can observe this by comparing a regular function vs a method
belonging to some class:
#include <iostream>
void greet() {
std::cout << "Hello World\n";
}
class Human {
public:
void greet() {
std::cout << "Hello World\n";
}
};
int main() {
greet();
Human human = Human();
human.greet();
}
Output:
$ g++ test.C
$ ./a.out
Hello World
Hello World
Both may output the same thing but under the hood is where the differences shines. Note: I’ll be only showing the code of interest.
For greet:
Dump of assembler code for function _Z5greetv:
0x0000000000401126 <+0>: push %rbp
0x0000000000401127 <+1>: mov %rsp,%rbp
0x000000000040112a <+4>: mov $0x402280,%esi
For Human::greet:
Dump of assembler code for function _ZN5Human5greetEv:
0x000000000040115c <+0>: push %rbp
0x000000000040115d <+1>: mov %rsp,%rbp
0x0000000000401160 <+4>: sub $0x10,%rsp
0x0000000000401164 <+8>: mov %rdi,-0x8(%rbp)
0x0000000000401168 <+12>: mov $0x402280,%esi
For greet (_Z5greetv), we can immediately tell that the function takes in no arguments both by the mangled name (i.e. mangled name ends with v to indicate its parameter is void)
and from the disassembled code. However, the same cannot be said for Human::greet. The mangled name _ZN5Human5greetEv does suggest that the method does not take in any parameter
and hence the suffix v for void. But observe the following line in <+8>:
mov %rdi,-0x8(%rbp)
This is our implicit argument, this, which contains the address of the object itself. We can observe this via gdb:
(gdb) p &human
$2 = (Human *) 0x7fffffffdc4f
...
(gdb) i r rdi
rdi 0x7fffffffdc4f 140737488346191
Notice our rdi register contains the same address as our object human: 0x7fffffffdc4f.
Software Version Numbers are Weird
January 28, 2025
It is important to install the right version of dependencies, libraries, and software to obtain the desired features. I made the mistake twice thus far where I
misunderstood version numbers. Here’s my grievances about how software versioning system works in how incompatible it is to the numbering system we use in our
everyday life. Let’s look at FileUtils.readFileToString():
public static String readFileToString(File file,
Charset charsetName)
throws IOException
Reads the contents of a file into a String. The file is always closed.
Parameters:
file - the file to read, must not be null
charsetName - the name of the requested charset, null means platform default
Returns:
the file contents, never null
Throws:
NullPointerException - if file is null.
IOException - if an I/O error occurs, including when the file does not exist, is a directory rather than a regular file, or for some other reason why the file cannot be opened for reading.
Since:
2.3
I am trying to compile some Java framework into a Jar at work and encountered an issue with readFileToString(). As specifying Charset is only available in
version 2.3 of commons-io, I “upgraded” the version in pom.xml. It turns out I downgraded because 2.3 < 2.15 and not the other way around.
In Math, 2.3 and 2.30 are the same thing. In science, these have the same quantity but differ in precision or certainty of the measurement. However,
in software, version numbers work differently. The common pattern is <major>.<minor>.<patch> which is commonly abbreviated as x.y.z. When comparing between
two version numbers, one must order by looking at the major, minor and patch number as separate whole numbers and not as a number. Of course, 1.1.1 is not a number
but I am blind. If you compare the major, minor, and patch separately, you can easily realize that 2.3 < 2.30 because 3 < 30 or 2.3 < 2.15 because 3 < 15.
Edit: One way to compare version numbers is to think of comparing it as if it’s a coordinate except there is a precedence order of the coordinates where one
compares the value in the first slot x, then second slot y and then lastly z before determining if the two versions are equal.
view is just vim in disguise
January 23, 2025
I recently found out accidentally at work that vim and view were the same thing when I happened to be editing a file on view instead of my beloved vim editor.
This should not come to any surprise, plenty of documentation will state this such as the man pages:
$ man -Leng view
VIM(1) General Commands Manual VIM(1)
NAME
vim - Vi IMproved, a programmer's text editor
SYNOPSIS
vim [options] [file ..]
vim [options] -
vim [options] -t tag
vim [options] -q [errorfile]
ex gex
view
gvim gview vimx evim eview
rvim rview rgvim rgview
Interestingly, the man pages for view points to vim and we can see all sorts of different types of editors listed along with it such as gvim.
If we take a look at AIX 7.3 documentation:
Starts the vi editor in read-only mode.
Taking a look at my local system (Fedora 41), we indeed see that is the case:
#!/usr/bin/sh
# run vim -R if available
if test -f /usr/bin/vim
then
exec /usr/bin/vim -R "$@"
fi
# run vi otherwise
exec /usr/libexec/vi -R "$@"
However, here’s where things gets weird. At work, view was a pointer to vi:
$ realpath view
/usr/bin/vi
However, on my other development machine, view was simply another binary that had the same md5sum. This has made me theorized that vi checks its name to
see whether or not to open the file in read-only mode based if it started with the name view. So I made an experiment by creating a new “binary” called view-pika (by creating a link to vim).
The result was as I theorized: it opened the file as READ-ONLY. I’ll go a deeper dive on my blog sometime this week
to understand why (spoiler, it’s essentially what I theorized).
My Thoughts on the Future of Firefox
January 21, 2025
I’ve been a Firefox user since around 2010 and tried various “flavors” of Firefox including Aurora (a build of Firefox version that is more stable than their nightly builds but less polished than the Beta version) and Firefox Developer Edition. I was also hyped for the short-lived FirefoxOS where I developed my first “mobile” application. Back around 2011, the marketshare between Internet Explorer, Firefox, and Chrome were relatively shared among each other having a 36.6%, 28.5%, and 20.2% of the market respectively by July 2011. Google Chrome was the new kid in town that reportedly was faster than Internet Explorer and was quickly eating up Internet Explorer’s marketshare. Microsoft’s domaince after killing netscape came to an end after it kept failing to compete with with Chrome and Firefox. Internet Explorer became such a pathetic state that its only use was to install Chrome or Firefox, there’s even a funny webtoon created in 2018 that makes fun of this titled Internet Explorer by Merryweather Comics

While I love Firefox, I am no longer optimistic of its survival considering it’s lifeline is now at risk ever since the DOJ’s ruling against Google’s monopoly on online searches. For context, Firefox has been receiving funds from Google since 2005 and it eventually became its primary source of revenue. Surprisingly, Firefox made the default search engine to Yahoo in 2014 but went back to Google, something I was not aware of or something I forgotten after switching it to Google. The fact that over 80% of Firefox’s revenue comes from Google means it has become an entity that cannot survive without the lifeline that its competitor graced to Firefox.
While not major, Firefox was yet slapped again after the winter holidays with the news that the Linux Foundation with its industrial partners like Google, Microsoft and Meta will be funding Chromium developers. Chromium is the open source web browser maintained by Google and is the basis for Google Chrome, Edge, Opera, Brave, and many other Chromium based browsers and applications including the disgusting Electron applications. Firefox is left in the dark, behind its peers and likely to fade in obscurity due to the lack of funding and support from other projects and organizations.
I’ll be using Firefox as long as I can but even I have to admit, Firefox’s performance is inferior to Google. For an entire year, I had to resort to using Brave to watch anime and still do to open my online textbooks for school as they either render weirdly or just not load at all. At the beginning of 2024, I thought there was a chance of Firefox’s revival with Manifest v3 removing a lot of the capabilities that adblockers had previous access to effectively prevent those annoying and malicious ads.
In my opinion, privacy browsers such as Brave will take over the flock who will or had migrated from Chrome due to concerns of their privacy and the retirement of Manifest v3. While Firefox may benefit from the small migration of ad-hating users from Chrome, I do not forsee Firefox being able to compete at the trajectory it is going at.
On other news, I wonder how far LadyBug will go.
The Sign of Char in ARM
January 15, 2025
The following below has a value that is vague:
char i = -1;
The issue with the above line is that the value of i is not immediately obvious as compilers for different architectures could treat this as signed or unsigned.
The signedness of a data type can be simply thought as whether or not there is a dedicated sign bit that indicates whether or not the number is postive or negative.
In Robert Love’s section on “Signedness of Chars” (Chapter 19 - Portability) of his book on the Linux Kernel Development, he notes that on some systems such as in ARM
would treat char as unsigned which goes against the logic of us AMD64 (x86-64) programmers. Effectively, the value of i will be stored as 255 rather than -1.
The reason for this is apparently due to performance.
Let’s verify this on my Raspberry Pi 4 machine running Linux:
char i = -1;
if (i == 255) {
printf("char is unsigned\n");
}
if (i == -1) {
printf("char is signed\n");
}
Result: char is unsigned
Therefore to make your code portable, one should ensure to explicitly state whether or not char is signed or unsigned instead of making assumptions if they know
their char will lie outside of 0 to 127.
I heard rumours that Apple may treat the signedness of char as signed instead but I unfortunately do not have access to an Apple ARM development machine to
verify this myself.
Maybe I’ll examine this more in my blog by examining what is going on under the hood and compare this with amd64 and whether or not QNX makes this change as well.
Note: I purposely omitted how signed bit works and the 2’s complement
A First Glance at Raspberry Pi 4 Running QNX 8.0
January 4, 2025
I recently purchased a Raspberry 4 to fiddle around with QNX 8.0 that has been released to the educational and hobbyist community. Being frustrated with running QNX virtual machines via Momentics, I decided it would be much easier to run QNX on a piece of hardware. I do not know if it is just me but I find my newly created virtual machines have a one-time boot lifespan. Any attempts to restart my virtual machines via Momentics, I would have network related issues and therefore would not be able to connect to the virtual machine remotely. This means that I cannot transfer files. I long forgotten how to create QNX image and run them on QEMU via commandline so I took the opportunity to buy myself a raspberry Pi (tbh I was just being lazy to resolve my issues).
Anyhow, enough idle chatter. Upon booting QNX on the Raspberry Pi, you’ll be first greeted with what appears to be demolauncher (though I did not confirm this):
Honestly this screen is annoying because I have to connect a mouse to simply open a terminal. Once authenticated, the terminal will greet you with a message along with a few bundled samples you can try:
Welcome to QNX 8.0!
This QNX 8 target is now ready for your QNX applications. There are
some sample applications included here to help you get started with
development. Find the source code for most of them at gitlab.com/qnx.
Here's how to run some of the bundled samples:
|------------------|----------------------------------------------------------|
| $ gles2-gears | Displays hardware-rendered content using OpenGL ES 2.x. |
| $ gles2-maze | Shows how to use texture, vertex, and fragment shaders. |
| $ vkcubepp | Demonstrates 3D rendering capabilities using Vulkan. |
| $ camera_example | Displays a simulated camera signal or live camera feed. |
| $ st | The default terminal. Run it to open a new instance. |
| $ blinq | A simple web browser. Make sure your system date is set. |
|------------------|----------------------------------------------------------|
(You can use ALT-TAB to switch between windows.)
Have questions? Find the community on Reddit at r/QNX, ask on StackOverflow,
or log an issue at https://gitlab.com/qnx .
Below are some of the bundled samples mentioned above along with some additional samples that I found on the image
The sample renderings are for illustration purposes only. To post them on the internet within a resaonable size, I had to significantly reduce the quality of the recordings:


gles2-gears or gless3-gears
gles2-maze


gless2-teapot
vkcubepp

camera_example: brings back memories of SMPTE color bars from the old days
As one can observe, most of these samples demonstrate graphical rendering using either OpenGL 2 (and 3) or Vulkan. I do think it is quite a neat demo but it does not demonstate QNX’s potential and abilities. It is hard to demonstrate QNX’s abilities without going into the weeds and pushing the OS. I did not fiddled around with QNX much so to be honest, these graphical demos surprised me as I haven’t seen QNX having anything graphical aside from the QNX 1.44MB Demo disk and QNX 6.5. I am more used to the plain old terminal experience I had with QNX 7 and 7.1.
st is a useful command to spawn a new terminal without going to the awful welcome screen and manually press the button to spawn a new terminal. As much as
I dislike the welcome demo screen, the page demonstrated to hobbyists that QNX raspberry Pi image has graphical capabilities that they can utilize for their own
side projects. The blinq browser as stated in the description is indeed a simple web browser.
There is nothing impressive about the web browser, as advertised, it is a bare bone web browser that can be quite slow. Weirdly enough, the web browser is not able to immediately report that a webpage does not exist. I do not know if that is an issue with the browser itself or the default network settings because it would load a non-existing page forever (well to be more precise, I gave up waiting).
Unsurprisingly, blinq is a Chromium based browser that is severely out of date.

There are a good number of useful binaries bundles in the raspberry pi image by default:
One of the features I greatly appreciate is the screenshot and vncserv utilities to take screenshots and access the machine remotely with graphical interface respectively.
Hopefully we can see some interesting projects from the hobbyist community in the near future.
</div>
</div>
</body> </html>